2015-11-30:对103道PAT题目做简单的总结:
1001 A+B Format (20) string处理,注意正负号
1002 A+B for Polynomials (25) 直接建立两个数组,相加输出
1003 Emergency (25) Dijkstra+DFS
1004 Counting Leaves (30) 计算每层叶子节点的数量
1005 Spell It Right (20) 字符串操作,计算digit总和并输出英文
1006 Sign In and Sign Out (25) 重写cmp进行排序
1007 Maximum Subsequence Sum (25) 最长连续子序列的和
1008 Elevator (20) 计算电梯时间
1009 Product of Polynomials (25) 多项式相乘,直接创建1000*1000+1个数组
1010 Radix (25) 重点:radix可以>=35,二分法查找radix
1011 World Cup Betting (20) 按照公式计算
1012 The Best Rank (25) 注意分数相同,排名相同
1013 Battle Over Cities (25) 使用并查集
1014 Waiting in Line (30) 银行排队模拟,一分钟一分钟地遍历
1015 Reversible Primes (20) 进制转换,质数判定
1016 Phone Bills (25) 排序,分类
1017 Queueing at Bank (25) 银行排队模拟
1018 Public Bike Management (30) Dijkstra+DFS
1019 General Palindromic Number (20) 回文判定+进制转换
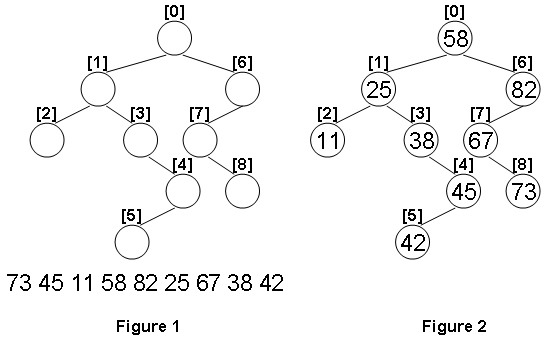
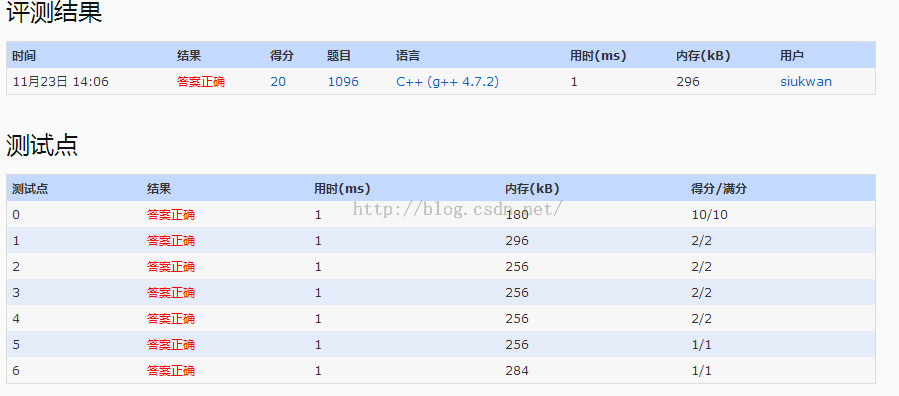
1020 Tree Traversals (25) 后序+中序还原二叉树
1021 Deepest Root (25) BFS求最深的根,并查集。
1022 Digital Library (30) 哈希
1023 Have Fun with Numbers (20) string 大整数运算
1024 Palindromic Number (25) 回文判断(可以考虑manacher)
1025 PAT Ranking (25) 排名,排序
1026 Table Tennis (30) 队列模拟,30秒的四舍五入
1027 Colors in Mars (20) 10进制转换成13进制
1028 List Sorting (25) 排序,strcmp
1029 Median (25) 重点:二分法求两个数的中位数
1030 Travel Plan (30) Dijkstra+DFS
1031 Hello World for U (20) string处理
1032 Sharing (25) 求两个链表的公共点
1033 To Fill or Not to Fill (25) 重点:加油问题,队列,数组
1034 Head of a Gang (30) 并查集
1035 Password (20) 简单的string处理
1036 Boys vs Girls (25) 简写的排序,重写cmp比较函数
1037 Magic Coupon (25) 简写的排序,重写cmp比较函数
1038 Recover the Smallest Number (30) 贪心算法,注意贪心标准
1039 Course List for Student (25) 哈希查询,注意超时
1040 Longest Symmetric String (25) 最长回文字串
1041 Be Unique (20) 简单的哈希
1042 Shuffling Machine (20) 简单的数组位置更换
1043 Is It a Binary Search Tree (25)重点:写两个函数进行判断BST,MirrorBST
1044 Shopping in Mars (25) 尺取法求连续子序列的和
1045 Favorite Color Stripe (30) 动态规划,LCS变形
1046 Shortest Distance (20) 简单的和累加(算是DP)
1047 Student List for Course (25) 重点:选择合适的数据结构
1048 Find Coins (25) 和twosum一样,使用hash遍历一次
1049 Counting Ones (30) 重点:计算‘1’的个数,扩展到计算‘0’的个数
1050 String Subtraction (20) 简单的string处理
1051 Pop Sequence (25) 栈模拟操作
1052 Linked List Sorting (25) 排序,注意head=-1的情况(段错误)
1053 Path of Equal Weight (30) 求根到叶子节点的权重和(DFS)
1054 The Dominant Color (20) moore投票法
1055 The World’s Richest (25) 重点:根据题目特点选择合适的数据结构
1056 Mice and Rice (25) 模拟,注意排名的规则
1057 Stack (30) 重点:栈+树状数组+二分查找
1058 A+B in Hogwarts (20) string+进制转换
1059 Prime Factors (25) 质因数分解,注意输入为1的情况
1060 Are They Equal (25) string处理
1061 Dating (20) string处理
1062 Talent and Virtue (25) 根据要求排序,重写cmp比较函数
1063 Set Similarity (25) 重点:使用合适的数据结构来求集合的相似度
1064 Complete Binary Search Tree (30) 创建完全二叉搜索树,进行中序遍历(记录地址),然后再填值
1065 A+B and C (64bit) (20) string,大整数相加
1066 Root of AVL Tree (25) 重点:AVL树的基本操作
1067 Sort with Swap(0,*) (25) 每次都确保*移动在最终位置,注意优化
1068 Find More Coins (30) DFS
1069 The Black Hole of Numbers (20) string操作
1070 Mooncake (25) 贪心,单位价格高的优先
1071 Speech Patterns (25) 哈希求出现最多的单词(注意题目对单词的定义)
1072 Gas Station (30) 循环+Dijkstra,求出每个加油站到各个屋子的最短路程
1073 Scientific Notation (20) 科学计数法,还原出原数字,string操作
1074 Reversing Linked List (25) 链表翻转,把链表复制到数组,然后再翻转
1075 PAT Judge (25) 统计分数进行排名,重写cmp比较函数
1076 Forwards on Weibo (30) 层序遍历
1077 Kuchiguse (20) 简单的string处理
1078 Hashing (25) 哈希的平方探测实现
1079 Total Sales of Supply Chain (25) 层序遍历
1080 Graduate Admission (30) 事件模拟
1081 Rational Sum (20) 分数相加,gcd(扩展学习lcm的计算)
1082 Read Number in Chinese (25) string处理
1083 List Grades (25) 哈希,排序
1084 Broken Keyboard (20) 哈希
1085 Perfect Sequence (25) M<=m*p,二分法查找,排序
1086 Tree Traversals Again (25) 重点:利用栈进行中序遍历,还原二叉树
1087 All Roads Lead to Rome (30) Dijkstra+DFS
1088 Rational Arithmetic (20) 分数的四则运算
1089 Insert or Merge (25) 插入和归并排序(需要学习归并排序)
1090 Highest Price in Supply Chain (25) 层序遍历, 求最深的层
1091 Acute Stroke (30) 并查集
1092 To Buy or Not to Buy (20) 哈希
1093 Count PAT’s (25) 组合数统计
1094 The Largest Generation (25) 层序遍历
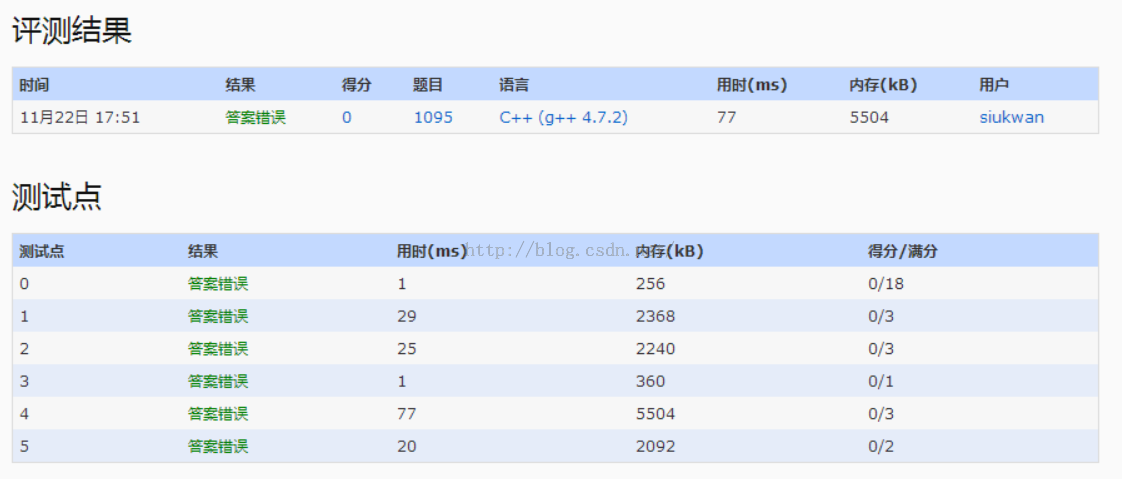
1095 Cars on Campus (30) 停车时间模拟
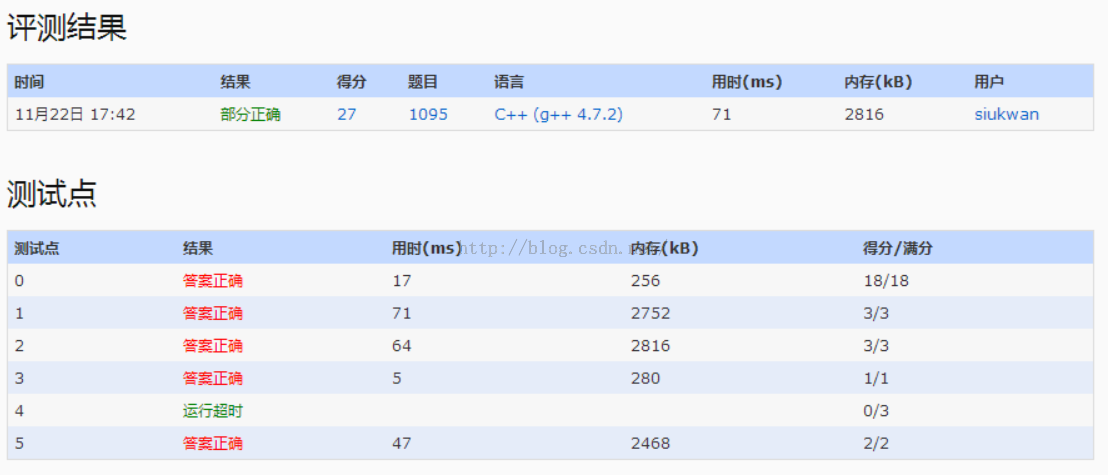
1096 Consecutive Factors (20) 重点:连续因数,DFS
1097 Deduplication on a Linked List (25) 哈希,链表操作
1098 Insertion or Heap Sort (25) 插入和堆排
1099 Build A Binary Search Tree (30) 中序遍历填值,建立二叉树
1100 Mars Numbers (20) 进制转换,10进制转13进制
1101 Quick Sort (25) 重点:判断能够作为pivot的元素,大根堆,小根堆的额外维护操作
1102 Invert a Binary Tree (25) 反转二叉树
1103 Integer Factorization (30) 因式分解,DFS