服务器原来配置了haproxy,因为对外只开放了80端口,没有开放22端口,所以haproxy配置了端口转发,规则如下(在/etc/haproxy/haproxy.cfg):
[shell]
#By http://blog.creke.net/
global
maxconn 5120
chroot /usr/share/haproxy
daemon
quiet
nbproc 2
pidfile /usr/share/haproxy/haproxy.pid
defaults
option httplog
option dontlognull
timeout connect 5s
timeout client 50s
timeout server 20s
listen http
bind :80
timeout client 1h
tcp-request inspect-delay 2s
acl is_http req_proto_http
tcp-request content accept if is_http
server server-http :8080
backend ssh
mode tcp
timeout server 1h
server server-ssh :22
[/shell]
意思是,绑定80端口,如果收到tcp连接请求,则延时2秒用于判断,如果是http协议,则转发到8080端口(webserver),否则,转发到22端口。
一、问题
这样配置后,基本问题不大,我们可以用过浏览器直接访问网址,也可以通过bitvise或者xshell指定80端口进行ssh连接。
但是,当我们使用linux进行连接时,会报错!刚开始连接的语句为:
[shell]
ssh xxx@xxxxx 80
[/shell]
错误如下:

它并没有把80自动识别为端口,而是默认连接22端口,于是我加了-p指定端口,如下:
[shell]
ssh xxx@xxxxx -p 80
[/shell]

这个时候,我们简单地看到ssh_exchange_identification错误,于是我搜索了一下,发现被告知是最大连接数或者是白名单黑名单的问题,于是我查了一遍最大连接数,/etc/hosts.allow ,/etc/hosts.deny,均没有发现特别的设置。
于是,继续使用-v打印详细的ssh连接信息:
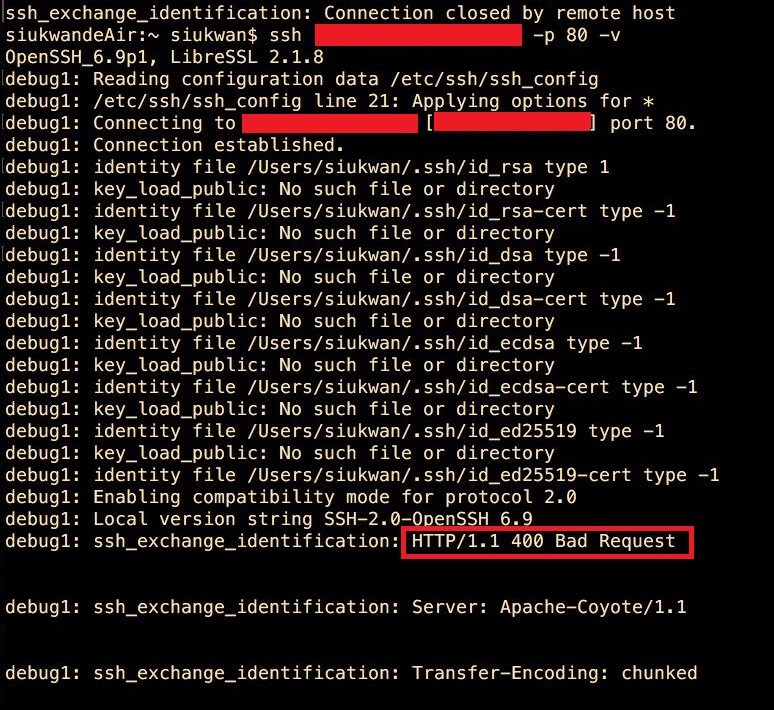
我们发现ssh连接会有Bad Request,这个明显是webserver的400回复啊,为了进一步确认,我在局域网内(局域网开放了8080端口,外网只开放80端口)ssh8080端口,结果和上面一样,如下图:
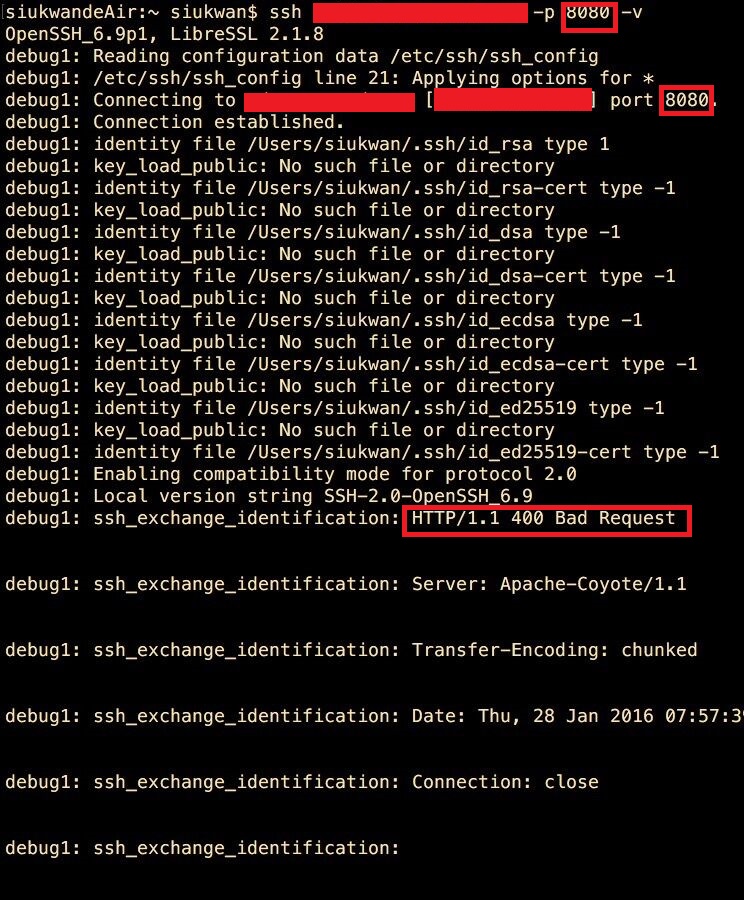
这个时候可以确认问题所在了,就是使用linux终端直接ssh的时候,haproxy还是直接转发到了8080端口,意思是我们的转发规则并没有写好。
二、测试与改进haproxy规则
使用nc命令查看payload,利用payload来进行判断,从而进行转发,命令如下:
[shell]
nc -l 8888|hexdump -C
[/shell]
我们先随便绑定一个8888端口,然后hexdump输出16进制信息,看看ssh与http请求有什么不一样的地方。输入上述命令后,会开始监听8888端口,于是我们可以对8888端口发送ssh和http请求:
ssh:直接在终端上面输入ssh localhost -p 8888即可
http:打开浏览器,输入网址localhost:8888
然后我们会有如下的结果:
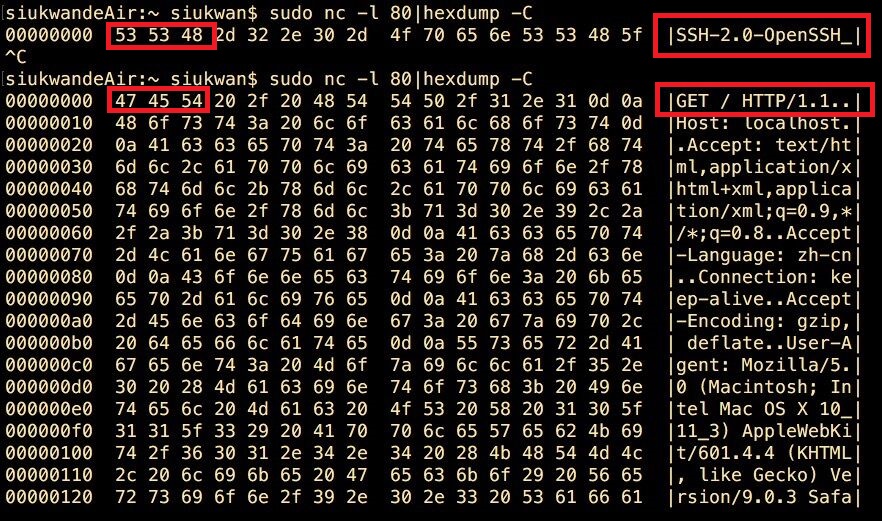
于是,我们可以对haproxy的转发规则进行修改,如下:
[shell]
#By http://blog.creke.net/
global
maxconn 5120
chroot /usr/share/haproxy
daemon
quiet
nbproc 2
pidfile /usr/share/haproxy/haproxy.pid
defaults
option httplog
option dontlognull
timeout connect 5s
timeout client 50s
timeout server 20s
listen http
bind :80
timeout client 1h
tcp-request inspect-delay 2s
#2016.1.28 siukwan改 G E T P O S P U T D E L etc
acl is_http req.payload(0,3) -m bin 474554 504f53 505554 44454c
# S S H
acl is_ssh req.payload(0,3) -m bin 535348
tcp-request content accept if is_http
server server-http :8080
backend ssh
mode tcp
timeout server 1h
server server-ssh :22
[/shell]
最后需要kill haproxy进程,然后使用如下命令启动:
[shell]
/usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg
[/shell]
使用终端直接指定80端口进行ssh连接,能够成功连接上!

