相关文章:
智力拼图问题–关于回溯和并行:单线程到多线程再到GPU编程的进阶(一)
智力拼图问题–关于回溯和并行:单线程到多线程再到GPU编程的进阶(二)
智力拼图问题–关于回溯和并行:单线程到多线程再到GPU编程的进阶(三)
这次介绍直立拼图问题的详细算法实现。
一、图形的数据结构
我采用了stl里面的vector来进行图形存储,并利用了C++11标准里面的大括号初始化来简化实现,如下:

每个图形都是一个二维数组vector<vector<char>> ,因为bool也是占用一个字节,char也是占用一个字节,为了统一矩阵和图形的打印、旋转等函数,统一使用vector<vector<char>>来存储。由于采用vector,所以我们轻易的得到每个图形的长宽。
二、矩阵的数据结构
如上面描述,采用vector<vector<char>>进行存储,实验时,实际填充效果如下:
133399
133996
111796
c77766
ccc786
a5c888
a5bb84
a55bb4
a252b4
a22244
使用char字符来存储,初始化矩阵的每个参数都是0,注意是0不是’0’,那么我们检测某个坐标是否被填充时,直接判断该位是0还是非零即可,非零表示已经被填充。
三、深度搜索算法的框架:

四、图形如何填充到矩阵mat中?
我们采用的是顺序填充算法,即首先搜索出矩阵第一个未被填充的空格,如下图:

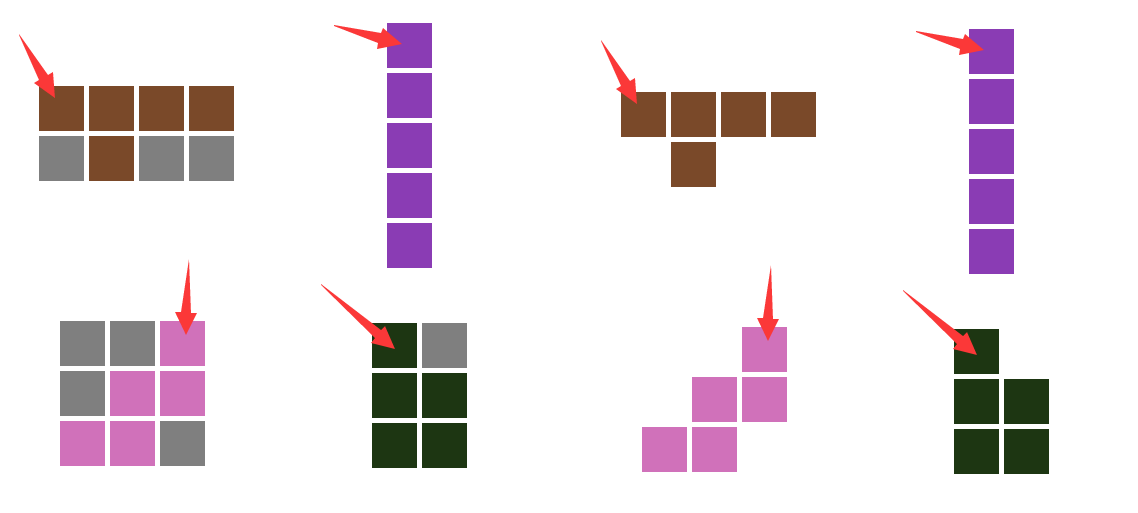
我们知道矩阵的第一个未填充坐标,那么如何把图形填充上去?所以,我们还需要求出图形的第一个有数据的坐标,即第一个为1的位置,如下图红圈的标注:

如下面的箭头指示,灰色表示空白部分。
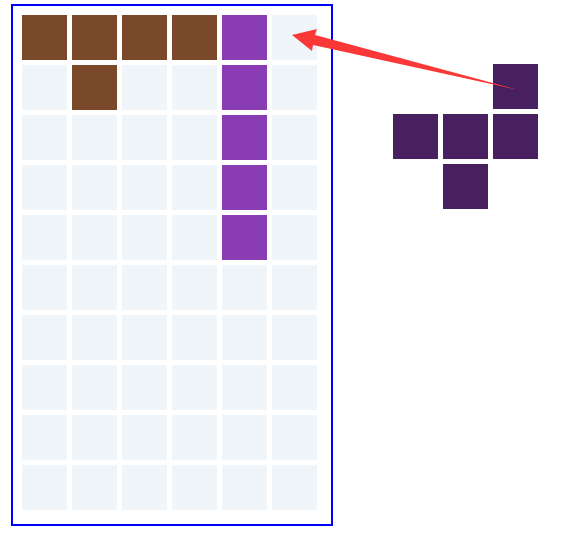
那么,我们有了矩阵的第一个未填充的位置,和图形的第一个有数据的的格子,只要把这个格子对着矩阵的未填充的位置填上去即可,如下图:
填充后:
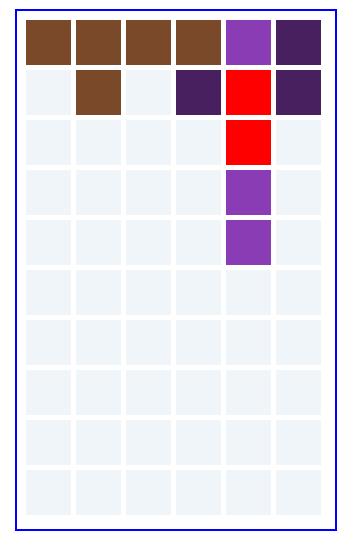
红色部分为冲突部分,证明填充不成功。
五、单线程实现
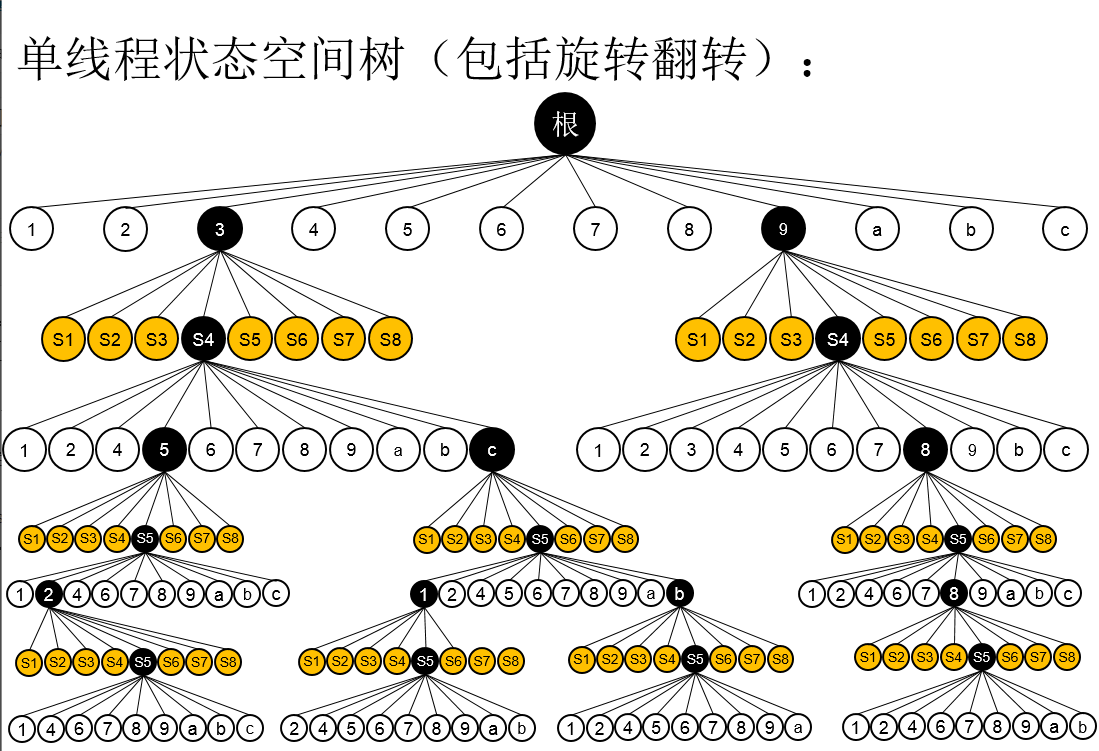
单线程实现较为简单,相当于写一个深度搜索的递归程序。状态空间树如下,实际上这是不够准确的,因为每个节点有多种变形,下面为了简化只画了4层。上面的深度搜索代码框架就是根据单线程画的。
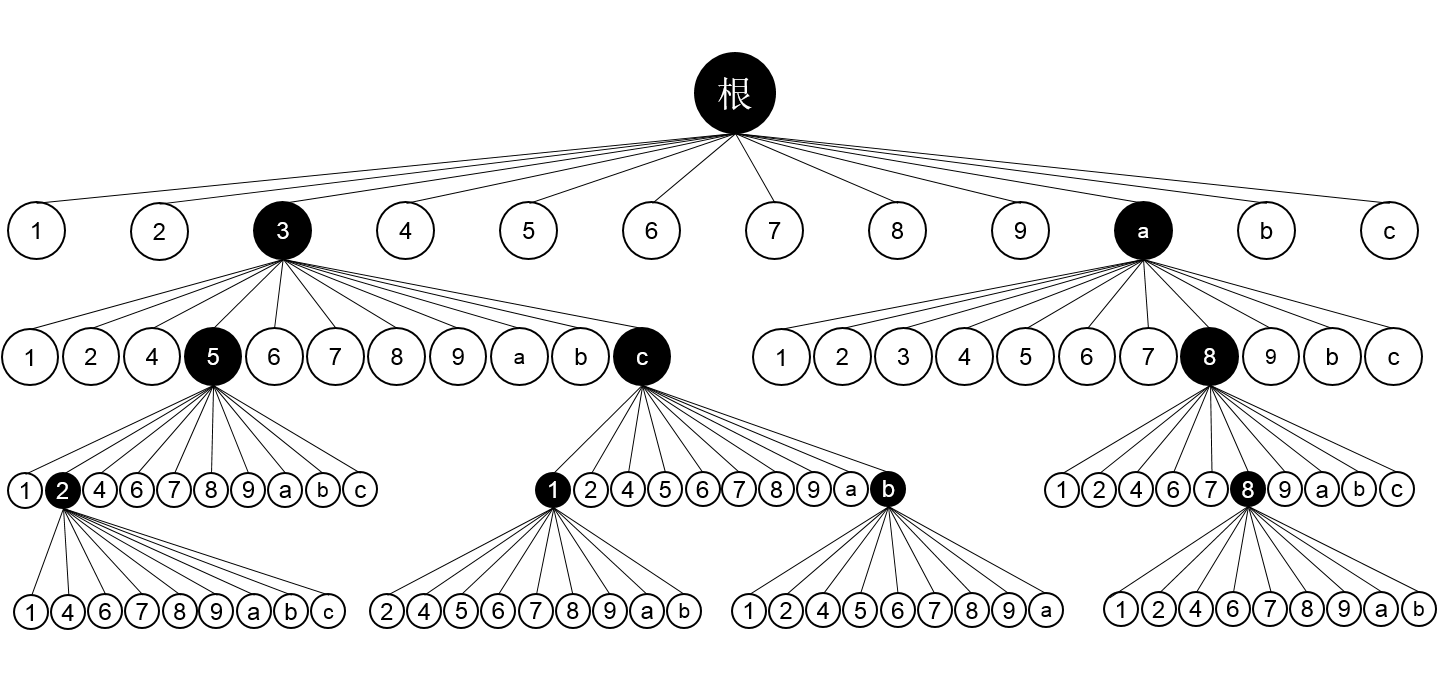
下面为更加准确的一个版本,每个节点包括了8种状态,但是后面为了简化表现,在画图的时候省去了这8种状态。
六、多线程实现
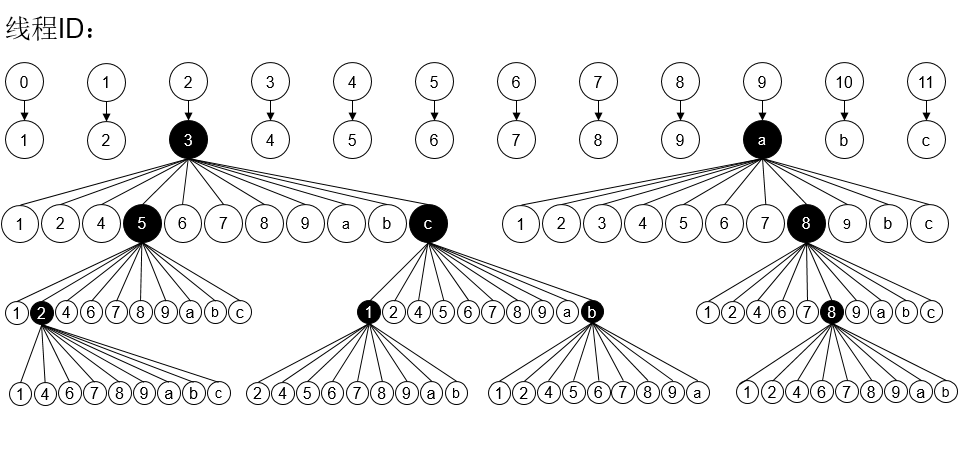
多线程实现,首先是要看电脑的CPU支持多少线程,我们的实验机器cpu是i7-4790K,是四核心八线程的,那么理论上最好是开7条线程,其中一条主线程用来检测7线线程的完成情况,一旦有线程工作完成并结束,马上开启另外一条。对于这道题目,我们可以把状态空间树的第一层(包含123456789abc节点的),分别划分为12条线程。如下图:
七、关于多线程的调度与优化问题
在六中,我们划分为12条线程,选取其中7条,先执行。但是实际上,这相当于人工调度线程,我们需要考虑挑选哪7条线程首先执行?按照顺序进行还是特意筛选?
按照顺序,先执行0到6号线程,那么可能在7到11号线程中,有些线程执行时间相当久,假设0到6号的线程执行时间为1个单位时间,7号线程执行时间为2个单位时间,其余的为1个单位时间,那么顺序执行线程,理论上最终需要3个单位时间。而假如我们先执行线程7,那么最终只需要2个单位时间。
特意筛选,这种方法有个明显的缺陷,就是假设初始化12个图形改变后,我们需要再次进行人工筛选。
那么最好的方法是什么?我们知道实验的电脑支持8线程,而实际上,电脑除了单纯执行我们的程序,还会执行其他的程序。线程数是超过8的,那电脑仍然能够运行起来,是因为操作系统本身就具有线程调度的功能。而实际上,我们只划分了12条线程,而不是12*11=132条线程,同时开启12条线程,CPU的上下文切换并没有占用太多的时间,对我们来说是可以接受的。
实际实验发现,状态少的线程会明显优先结束,CPU似乎是使用了时间片轮转的方法来执行线程。
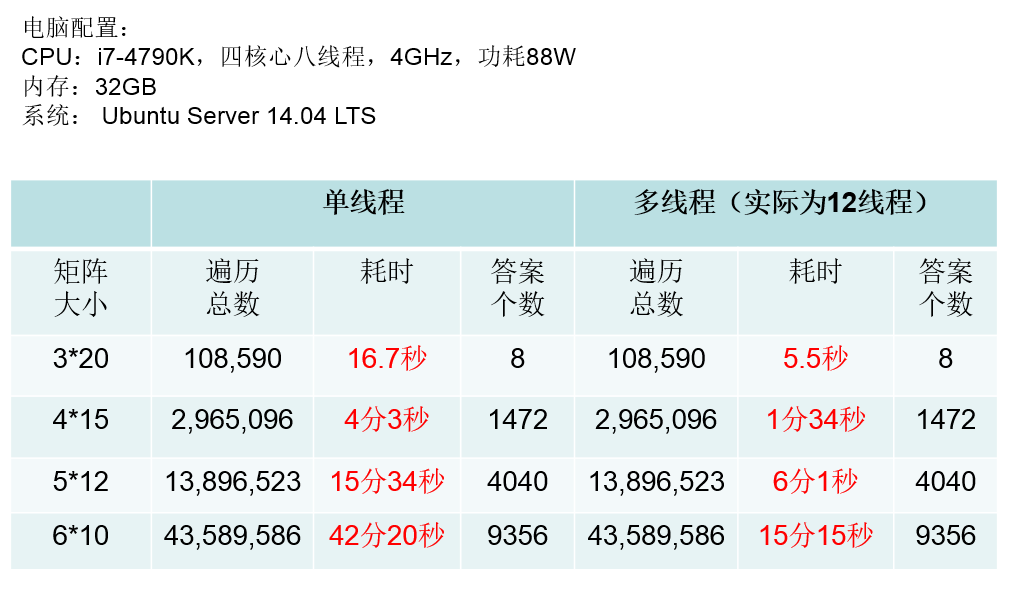
八、实验数据对比
遍历总数和答案个数一致,证明两个算法是正确的,其中主要关注运行时间即可,减少超过一半的运行时间。
九、源代码
由于编写的源代码兼容了windows和linux系统,并且兼容了单线程和多线程,代码较长,放在了github上面,网址为:https://github.com/siukwan/algorithm
十、更多的思考
经过上面的讨论,我们发现,这道题目的解法只有回溯(和暴力搜索没什么区别),但是通过改为多线程,我们看到了效率明显提升。既然要涉及到多线程编程,除了找核心更多的CPU还有别的方法吗?没错,多线程编程,实则和并行计算非常接近,既然涉及到并行计算,怎么可以忽略Nvdia的显卡!恰好我的电脑配置了4GB显存的GeForce 840M显卡,性能虽然中等,但是可以尝试!
在下一篇文章中我将会介绍如何把上面的问题通过GPU编程解决:
智力拼图问题–关于回溯和并行:单线程到多线程再到GPU编程的进阶(三)