相关文章:
智力拼图问题–关于回溯和并行:单线程到多线程再到GPU编程的进阶(一)
智力拼图问题–关于回溯和并行:单线程到多线程再到GPU编程的进阶(二)
智力拼图问题–关于回溯和并行:单线程到多线程再到GPU编程的进阶(三)
GPU编程–CUDA环境配置与简单例程
这一次,我们终于涉及到GPU了!通过GPU编程去求解智力拼图问题!
目前我在自身的windows8.1笔记本上面采用GPU编程,使用了英伟达CUDA7.5的toolkit,IDE采用的是VS2013.按照和示范教程可以参考:
正式转入正文!
一、多线程的模型
通过上一篇文章,我们知道,多线程编程,就是把一开始的12个图形,分别使用一条线程去遍历,相当于本来的状态空间树是12层的,现在减少为11层。
而GPU编程中,涉及到上万条线程,都是很常见的,那我们应该如何把状态空间树划分为成千上万条线程呢?下面给出一个解决方案:
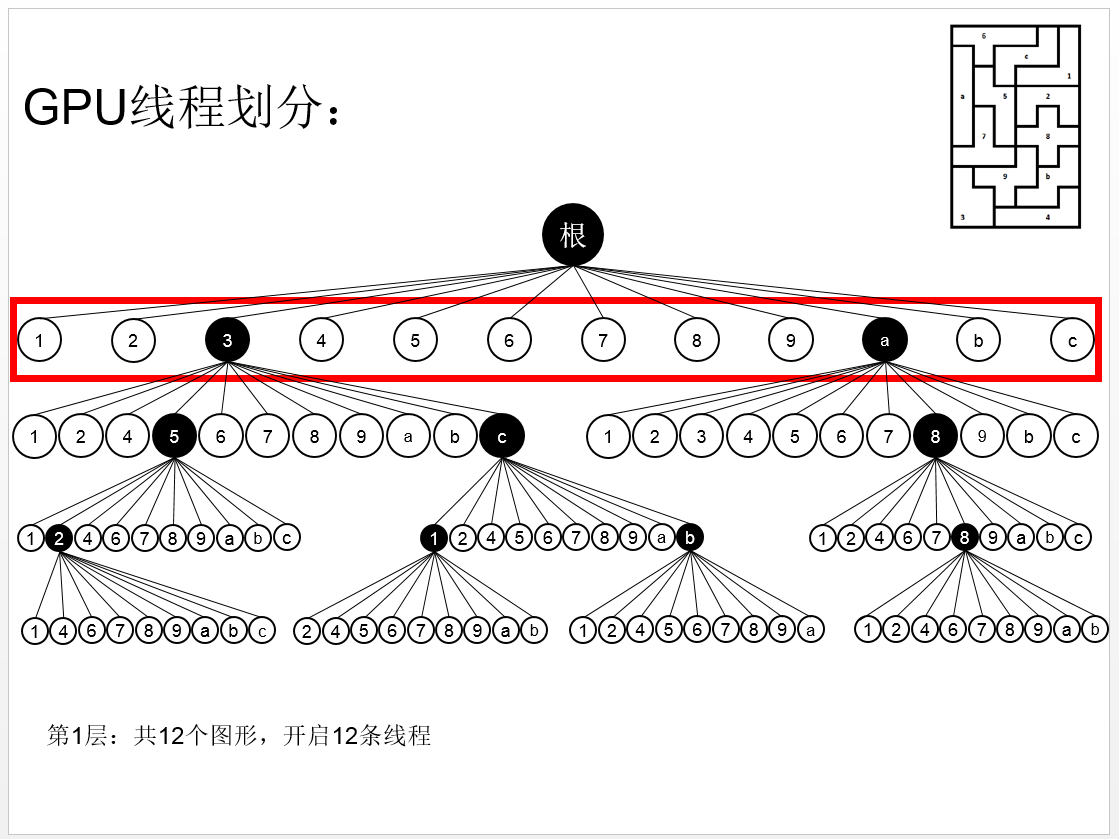
在多线程编程中,我们划分为12条线程,如下图:
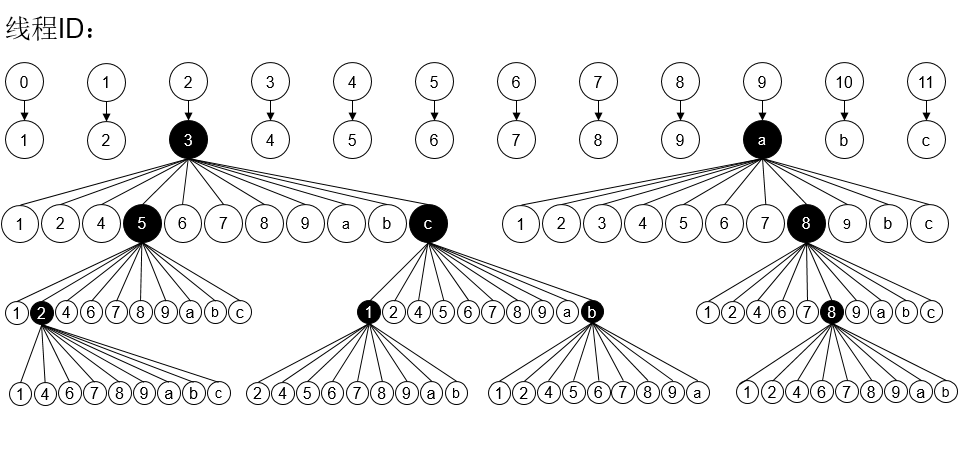
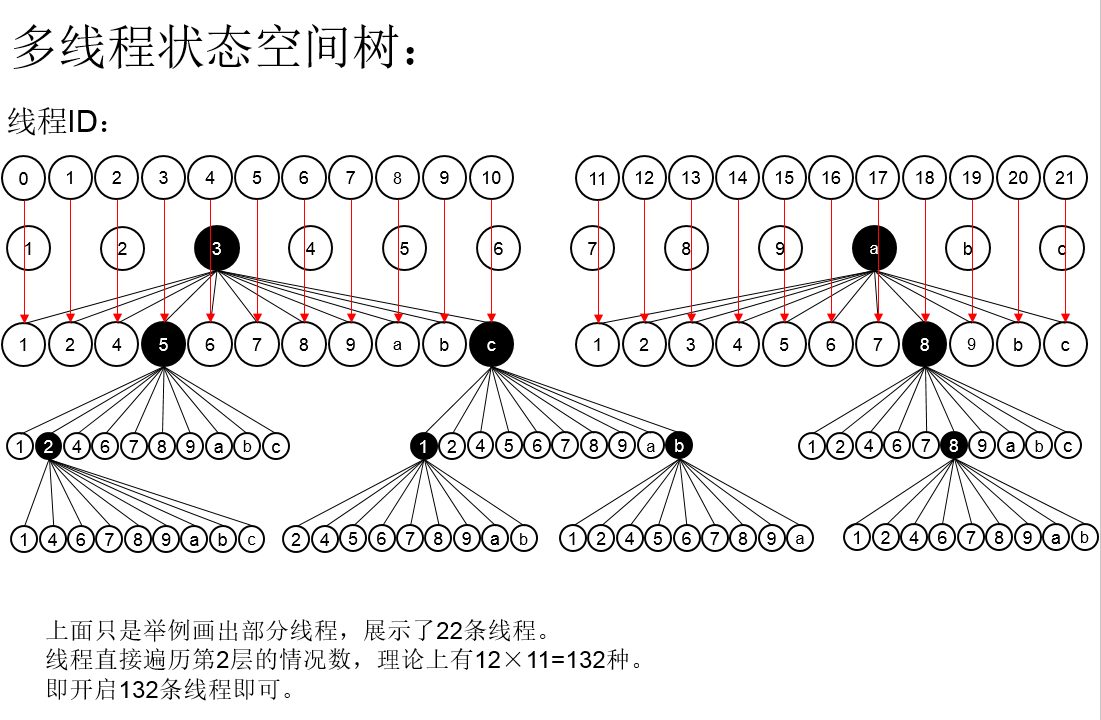
那做一个简单的转换,我们多深入数层,岂不是就能够划分更多的线程?如下图:
深入到第二层:
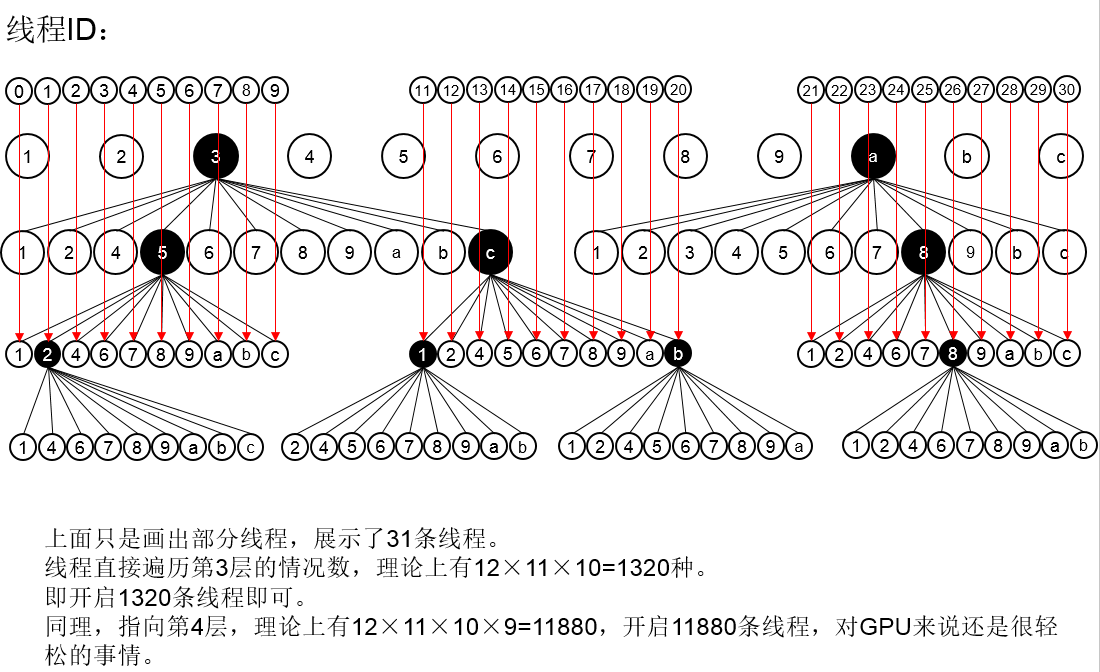
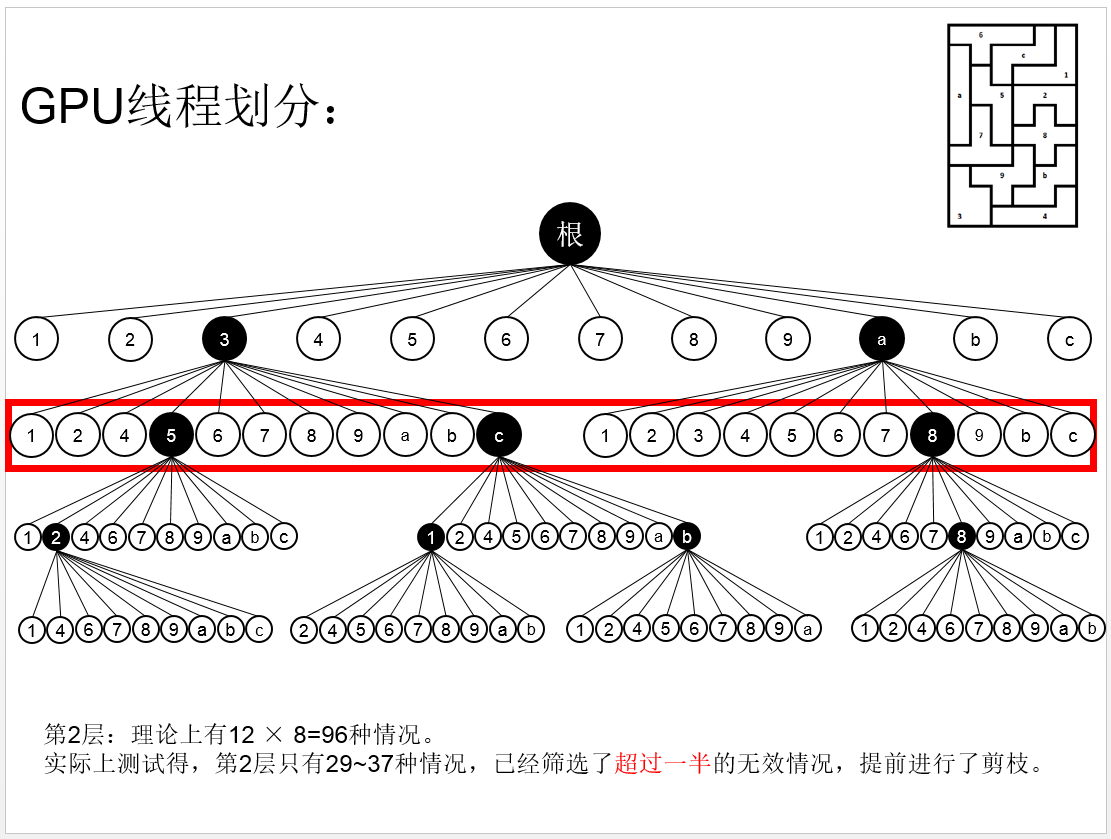
深入到第三层:
存在的问题:到了这里,你可能意识到,存在一些情况,在第二层就已经不合适了,即没有必要进入第三层。这是这个方法的一个缺陷,但是基于GPU强大的并行计算能力,我们先忽略这个问题,讨论每个线程的工作任务。
二、进行实验
我们假设深入到第三层,开启11880条线程,这对GPU来说确实是很轻松的事情。那么我们接下来讨论每条线程该做些什么样的工作。深入到第三层,树的深度是12,意味着我们还需要在每条线程里面进行深度搜索,最大的递归深度为12-3=9层。我们每条线程需要DFS9层。
好的,我们来实际操作。但是实际上,你们会发现,GPU能够进行大量的并行计算,是以牺牲计算性能来实现的,也就是说,GPU的每条线程,其运算能力是很弱的,分配到每条线程的内存空间也是十分有限的。我们在实验过程中,递归到第三层,就会出现显卡驱动崩溃的情况!如下图:
好吧,你们可能觉得我的显卡不够好,我的显卡型号是GeForce 840M,确实不是一个好显卡,那么我们来找一个好一点的显卡进行实验–GTX 960M!实验结果如下图:
很遗憾,依然崩溃了。我们充分体会到每个GPU线程计算能力的脆弱性。
三、再对多线程模型进行探讨
通过上面的实验室我们知道GPU线程无法递归那么深的深度(超过2深度就崩溃),无论你开启了一条GPU线程还是1万条GPU线程,只要递归深度超过了2,就崩溃了。
那既然GPU运算能力有限,我们能不能改变我们的多线程计算模型(并行计算模型)?经过两天的实验和探索,我们确实是找到了!
对于上面的遍历,我们采用的是DFS(深度优先搜索),深度优先搜索通过递归不断遍历,必然会导致栈的开销较大。那么我们是否可以采用BFS(广度优先搜索)?采用广度优先搜索,我们就可以避免了调用函数而导致开启的栈的开销。
还记得在第二点中提到的存在问题不?在每一层,都会有一些废弃的节点,假如我们按照bfs进行搜索,相当于对树进行层序遍历,这样就可以避免了废气的节点还会深入到下一层的情况!
既然有一定的合理性,那我们来重新编写程序来解决智力拼图!
四、使用BFS的并行计算模型
我们可以简单的理解为树的层序遍历。我们使用gpu对每一层的节点分配一个线程,而gpu运算只计算它下一层的可行解。
当该层的线程全部执行完毕,我们就有了下一层的可行解,也就是下一层的节点,这时,我们再次使用gpu对下一层的节点进行分配线程和计算。如此类推,理论上,我们使用调用gpu12次,那么就可以把这个12层的树给遍历完。
而且这种算法,在每一层遍历的时候,就已经去掉了一些不可能的情况,使得下一层的节点大大减少!如下图:
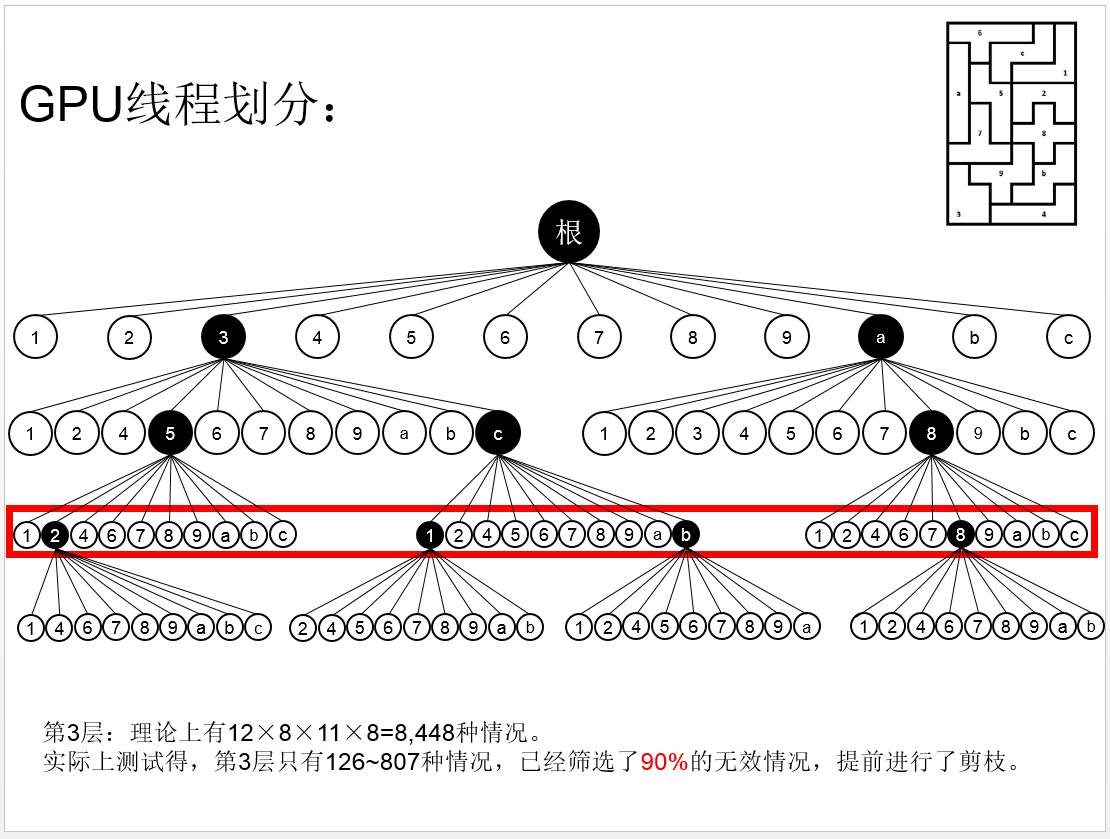
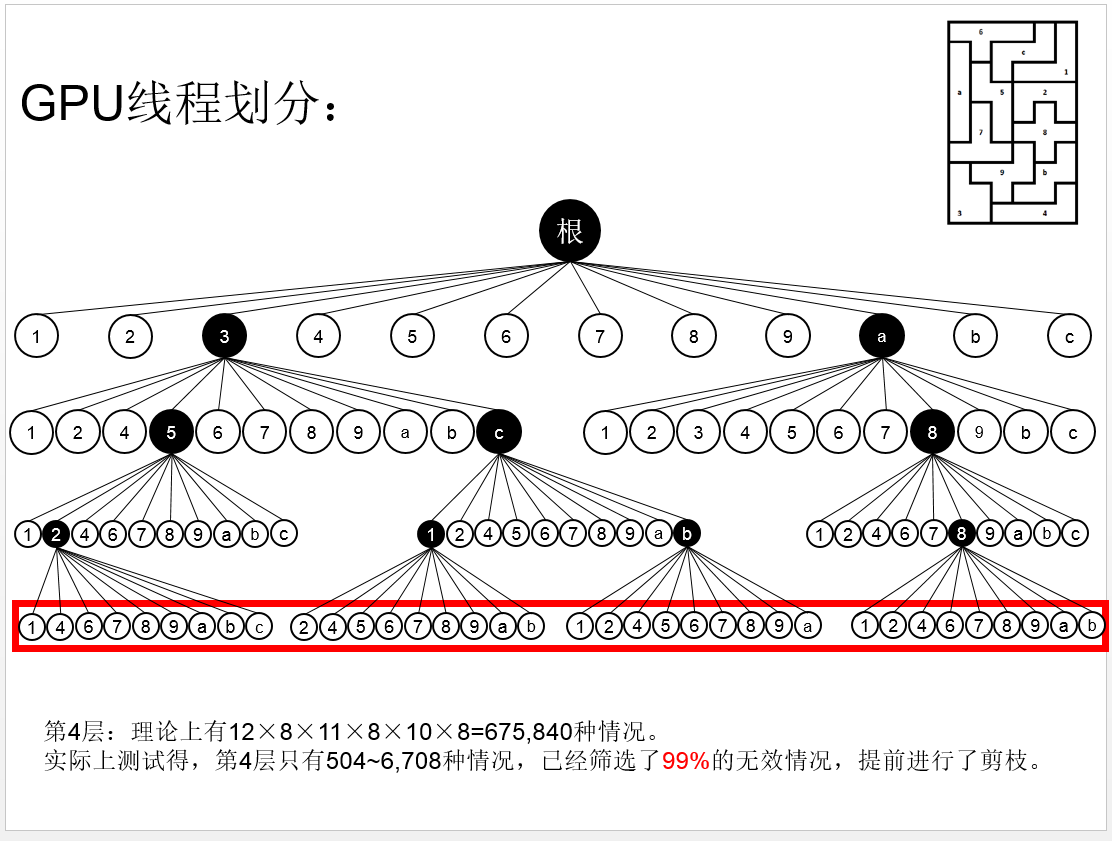
按照这个思想,我们编写了程序,代码在github上面:https://github.com/siukwan/algorithm
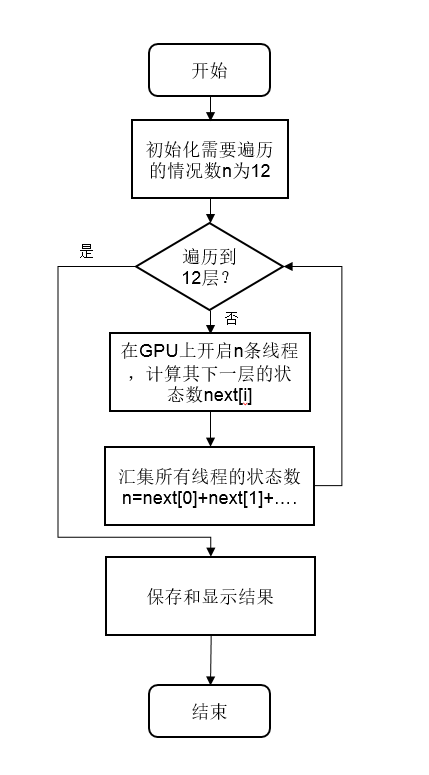
各层次线程开启数量:
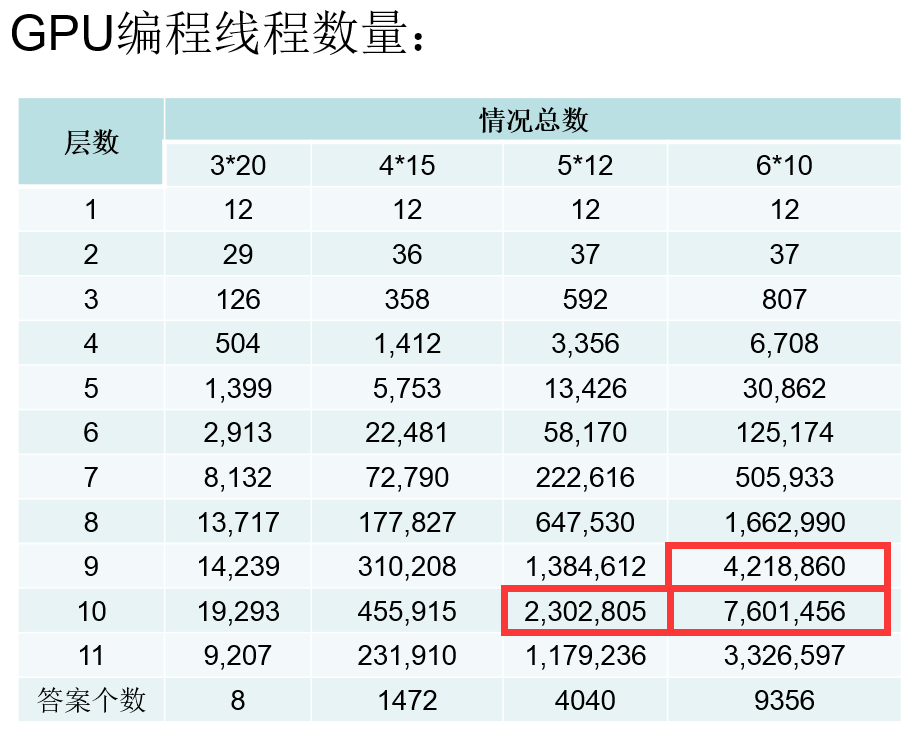
我们可以看到红框框住的几个数据,发现其需要处理的情况数量超过了200万,而实际测试知道我的显卡GT 840M最多只能开200万条线程,所以在这里我才用了循环拆分,为了减轻负担,我并没有同时开启200万条线程,设置了最多开启100万条线程,所以超过100万种情况的,我拆分为多次处理,每次最多处理100万种情况。
五、实验结果
使用了GPU后,其强大的线程并行能力着实让我们很吃惊,同时开启100万条线程毫无压力(1024个blocks,每个blocks开启1024条线程,共1024*1024)