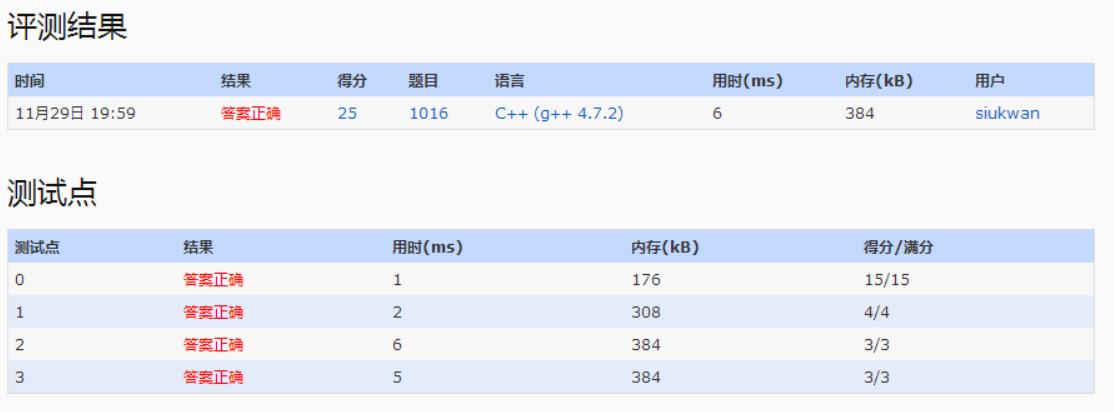
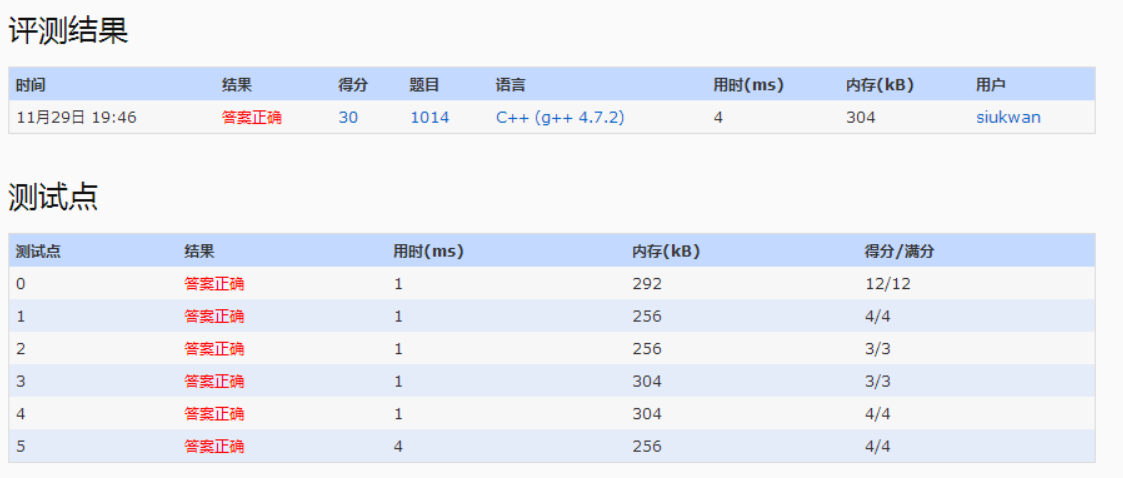
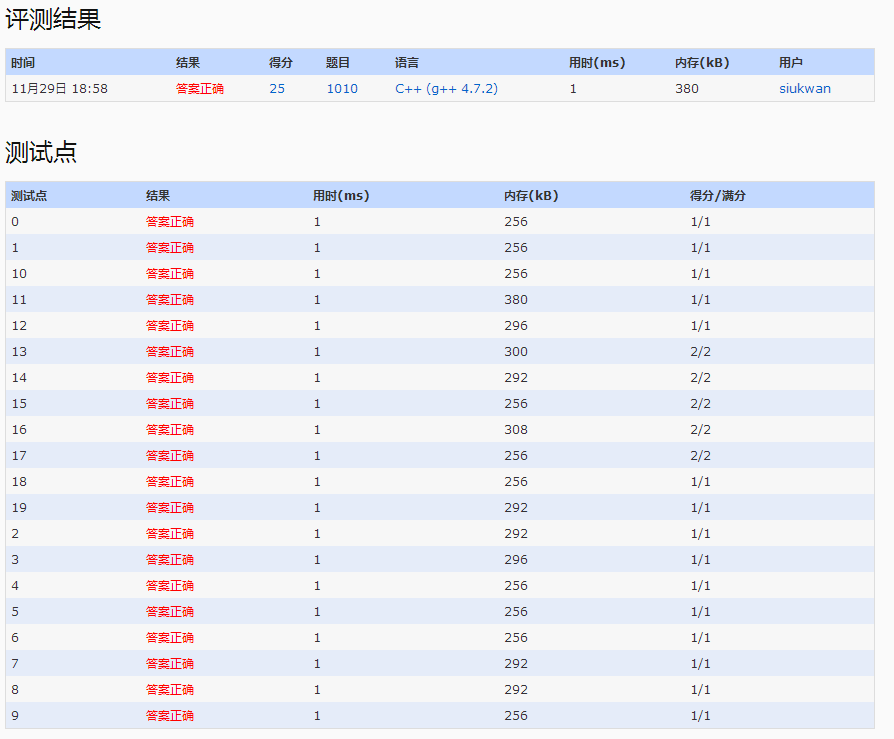
1.题目给出用户到达的时间和需要处理的时间,求出平均等到时间
2.在17:00:00前(包括17整)来的客户,都要确保一直执行完,即使超过了17点。譬如一个在8点来的客户,处理时间需要20小时,也需要同样服务完,然后处理队列中的客户。
3.只是对17:00:00后来的客户拒绝服务,用户在17:00:00前来,也需要放到队列中进行处理(和2的说法对应)。
4.逻辑顺序有问题,需要先插入,然后再减时间。
5.首次插入,需要判断时间是否合适。
6.直接对每一秒进行模拟,目前N=10000,K=100,对于N*K的复杂度,PAT能够接受,在400ms内。
Suppose a bank has K windows open for service. There is a yellow line in front of the windows which devides the waiting area into two parts. All the customers have to wait in line behind the yellow line, until it is his/her turn to be served and there is a window available. It is assumed that no window can be occupied by a single customer for more than 1 hour.
Now given the arriving time T and the processing time P of each customer, you are supposed to tell the average waiting time of all the customers.
Input Specification:
Each input file contains one test case. For each case, the first line contains 2 numbers: N (<=10000) – the total number of customers, and K (<=100) – the number of windows. Then N lines follow, each contains 2 times: HH:MM:SS – the arriving time, and P – the processing time in minutes of a customer. Here HH is in the range [00, 23], MM and SS are both in [00, 59]. It is assumed that no two customers arrives at the same time.
Notice that the bank opens from 08:00 to 17:00. Anyone arrives early will have to wait in line till 08:00, and anyone comes too late (at or after 17:00:01) will not be served nor counted into the average.
Output Specification:
For each test case, print in one line the average waiting time of all the customers, in minutes and accurate up to 1 decimal place.
Sample Input:
7 3 07:55:00 16 17:00:01 2 07:59:59 15 08:01:00 60 08:00:00 30 08:00:02 2 08:03:00 10
Sample Output:
8.2
[c language=”++”]
AC代码:
/*
1.在17:00:00前(包括17整)来的客户,都要确保一直执行完,即使超过了17点
2.只是对17:00:00后来的客户拒绝服务
3.逻辑顺序有问题,需要先插入,然后再减时间
*/
//#include<string>
//#include <iomanip>
#include<vector>
#include <algorithm>
//#include<stack>
#include<set>
#include<queue>
#include<map>
//#include<unordered_set>
//#include<unordered_map>
//#include <sstream>
//#include "func.h"
//#include <list>
#include<stdio.h>
#include<iostream>
#include<string>
#include<memory.h>
#include<limits.h>
using namespace std;
class customNode{
public:
int process, start, arrivalSecond, waitTime;
int calculateWaitTime();
customNode() :process(-1), start(-1), arrivalSecond(-1), waitTime(-1){};
};
int time2int(string a)
{//string转化为00:00:00到现在的时间
return ((a[0] – ‘0’) * 10 + a[1] – ‘0’) * 3600 + ((a[3] – ‘0’) * 10 + a[4] – ‘0’) * 60 + ((a[6] – ‘0’) * 10 + a[7] – ‘0’);
}
int customNode::calculateWaitTime()
{//计算等待时间
return start – arrivalSecond;
}
bool cmp(const customNode&a, const customNode&b)
{
return a.arrivalSecond < b.arrivalSecond;
}
int main(void)
{
int n, k;
cin >> n >> k;
int startTime = 8 * 3600;//8点
int endTime = 17 * 3600;//17点
vector<customNode> custom(0);
for (int i = 0; i < n; i++)
{
int hour, minute, second, process;
scanf("%d:%d:%d %d", &hour, &minute, &second, &process);
int arrivalTime = hour * 3600 + minute * 60 + second;
if (arrivalTime <= endTime)
{//小于17:00:00的才加入
custom.push_back(customNode());
custom.back().arrivalSecond = arrivalTime;
custom.back().process = process * 60;
custom.back().start = -1;
}
}
sort(custom.begin(), custom.end(), cmp);
n = custom.size();
int query = 0;
vector<int> window(k, -1);
//while (query < n && query < k && custom[query].arrivalSecond <= startTime)
//{//本来卡在了这里,插入时缺少判断时间是否合适
// window[query] = query;
// custom[query].start = startTime;//第一批到的人,记为0,即08:00:00开始处理
// query++;
//}
int now = startTime;
for (int i = startTime; query < n; i++)
{//注意结束条件是query>=n,即凡是压进队列的用户,都必须接受处理,17点后到来的用户已经不在队列中
now = i;
//先进行插入,遍历k个窗口
for (int j = 0; j < k; j++)
{
if (window[j] == -1 && query < n)//窗口为空闲时
{
if (custom[query].arrivalSecond <= now)
{//队列中还有客户,且客户的到达时间小于等于当前时间
window[j] = query;
custom[query].start = now;
query++;
}
}
}
//进行减时间,如8点到的用户,现在刚好是8点,process为1分钟,那么process已经-1,为0了,所以即使空出来,也得等到8点01分才能插入(即等到下一个周期)
for (int j = 0; j < k; j++)
{//遍历k个窗口
if (window[j] != -1)
{
int num = window[j];
custom[num].process–;
if (custom[num].process == 0)//当客户的处理时间为0时,代表结束
window[j] = -1;//窗口置为空闲
}
}
}
int waitTime = 0;
for (int i = 0; i < n; i++)
{
custom[i].waitTime = custom[i].calculateWaitTime();
waitTime += custom[i].waitTime;
}
if (n == 0)
printf("%.1f", 0.0);
else
printf("%.1f", waitTime / 60.0 / n);
cout << endl;
return 0;
}
[/c]