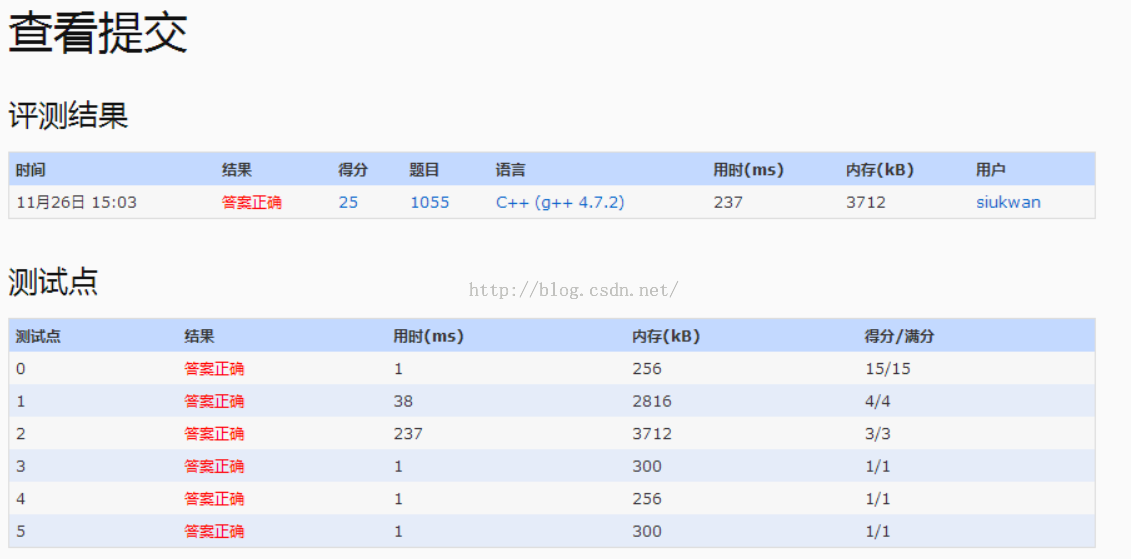
1.该题重点!题目给出一定的用户,包括用户年龄和净资产,要求后面按照年龄查询用户,按照一定的规则排序。
2.先把用户按照年龄大小排序,因为后面给出的是年龄范围,所以需要快速找出符合年龄要求的用户
3.建立一个年龄数组,该数组记录了以年龄x为左界时,用户数组的idx,以年龄x为右界时,用户数组的idx,通过年龄数组,就可以快速定位到用户数组的对应位置
4.刚开始,在查询输入时,直接定位到用户数组,把对应的用户数组段复制出来,进行排序,但是会超时(卡了还挺久的),然后仔细思考,发现用户数组的数量可能很大,<=100000,查询数量最大为2000,假如每次都复制100000,然后再进行排序,会严重浪费时间。
5.再观察题目,发现最终需要显示的数量最多只有100个,于是考虑建立一个小根堆,把它的大小维持在需要显示的数量showSum,最后复制输出即可。
为什么建立小根堆?我们的目的是要找出财富值最大的showSum个用户,建立小根堆,堆顶为showSum个用户中财富最小的,假如遍历用户j,发现用户j的财富值比小根堆的堆顶要大,那么把用户压入小根堆,再从小根堆中弹出堆顶即可。
Forbes magazine publishes every year its list of billionaires based on the annual ranking of the world’s wealthiest people. Now you are supposed to simulate this job, but concentrate only on the people in a certain range of ages. That is, given the net worths of N people, you must find the M richest people in a given range of their ages.
Input Specification:
Each input file contains one test case. For each case, the first line contains 2 positive integers: N (<=105) – the total number of people, and K (<=103) – the number of queries. Then N lines follow, each contains the name (string of no more than 8 characters without space), age (integer in (0, 200]), and the net worth (integer in [-106, 106]) of a person. Finally there are K lines of queries, each contains three positive integers: M (<= 100) – the maximum number of outputs, and [Amin, Amax] which are the range of ages. All the numbers in a line are separated by a space.
Output Specification:
For each query, first print in a line “Case #X:” where X is the query number starting from 1. Then output the M richest people with their ages in the range [Amin, Amax]. Each person’s information occupies a line, in the format
Name Age Net_Worth
The outputs must be in non-increasing order of the net worths. In case there are equal worths, it must be in non-decreasing order of the ages. If both worths and ages are the same, then the output must be in non-decreasing alphabetical order of the names. It is guaranteed that there is no two persons share all the same of the three pieces of information. In case no one is found, output “None”.Sample Input:
12 4 Zoe_Bill 35 2333 Bob_Volk 24 5888 Anny_Cin 95 999999 Williams 30 -22 Cindy 76 76000 Alice 18 88888 Joe_Mike 32 3222 Michael 5 300000 Rosemary 40 5888 Dobby 24 5888 Billy 24 5888 Nobody 5 0 4 15 45 4 30 35 4 5 95 1 45 50
Sample Output:
Case #1: Alice 18 88888 Billy 24 5888 Bob_Volk 24 5888 Dobby 24 5888 Case #2: Joe_Mike 32 3222 Zoe_Bill 35 2333 Williams 30 -22 Case #3: Anny_Cin 95 999999 Michael 5 300000 Alice 18 88888 Cindy 76 76000 Case #4: None
AC代码:
[c language=”++”]
//#include<string>
//#include<stack>
//#include<unordered_set>
//#include <sstream>
//#include "func.h"
//#include <list>
#include <iomanip>
#include<unordered_map>
#include<set>
#include<queue>
#include<map>
#include<vector>
#include <algorithm>
#include<stdio.h>
#include<iostream>
#include<string>
#include<memory.h>
#include<limits.h>
#include<stack>
using namespace std;
struct PeopleNode{
int age, netWorth;
char name[9];
PeopleNode() :age(-1), netWorth(-1){};
};
bool cmp(const PeopleNode&a, const PeopleNode&b)
{//根据年龄排序
if (a.age < b.age)
return true;
else
return false;
}
struct cmpHeap{//根据题目的显示规则排序
bool operator()(const PeopleNode&a, const PeopleNode&b)
{
if (a.netWorth > b.netWorth)
return true;
else if (a.netWorth == b.netWorth && a.age < b.age)
return true;
else if (a.netWorth == b.netWorth && a.age == b.age)
{
int asize = 0, bsize = 0;
for (int i = 0; i < 9; i++)
{
if (a.name[i] != 0)
asize++;
else
break;
}
for (int i = 0; i < 9; i++)
{
if (b.name[i] != 0)
bsize++;
else
break;
}
for (int i = 0; i < min(asize, bsize); i++)
{
if (a.name[i] < b.name[i])
return true;
else if (a.name[i] > b.name[i])
return false;
}
if (asize < bsize) return true;
else return false;
}
else
return false;
}
};
int main(void)
{
int peopleSum, querySum;
scanf("%d %d", &peopleSum, &querySum);
vector<PeopleNode> people(peopleSum);
vector<vector<PeopleNode>> agePeople(201);
for (int i = 0; i < peopleSum; i++)
{
scanf("%s %d %d", people[i].name, &people[i].age, &people[i].netWorth);
}
sort(people.begin(), people.end(), cmp);
vector<pair<int, int>> ageRange(201, { -1, -1 });
int idx = 0;
//计算年龄范围数组
for (int i = 0; i < ageRange.size(); i++)
{
if (idx < people.size())//确保idx在size内
{
if (idx == 0 && people[idx].age > i)
{//idx不进行++,而i++,直到i和age相等
ageRange[i].first = 0;
ageRange[i].second = -1;//以-1作为右边界,意思是不存在年龄小于等于i的人
}
else if (idx != 0 && people[idx].age > i)
{//idx不进行++,而i++,直到i和age相等
ageRange[i].first = idx;//i岁的搜索的起始idx,以idx作为左边界
ageRange[i].second = idx – 1;//i岁的搜索的终止idx,以idx-1作为右边界
}
else if (people[idx].age == i)
{//如果i等于年龄
ageRange[i].first = idx;
while (idx < people.size() && people[idx].age == i)
{//一直到age和i不相等
idx++;
}
ageRange[i].second = idx – 1;//第idx个人的年龄不等于i,第idx-1个人的年龄等于i
}
}
else if (i>0)
{//如果i的值大于0,且idx超出范围(即已经遍历完用户)
ageRange[i].first = people.size();//把i的左界设置为无效值
ageRange[i].second = ageRange[i – 1].second;//把i的右界设置为用户idx的最大值
}
}
for (int i = 0; i < querySum; i++)
{
int showSum, minA, maxA;
scanf("%d %d %d", &showSum, &minA, &maxA);
int sum = ageRange[maxA].second – ageRange[minA].first + 1;//求出以minA为左界,maxA为右界的people数量
printf("Case #%d:\n", i + 1);
if (sum > 0)
{//存在用户,sum的数量可能很大,用户取值<=100000,但是需要显示的数量<=100,所以用一个小根堆来维护需要显示的人
vector<PeopleNode>::iterator ite = people.begin();
priority_queue<PeopleNode, vector<PeopleNode>, cmpHeap> q;
for (int j = 0; j < sum; j++)
{
if (q.size() == showSum && q.top().netWorth <= (ite + j + ageRange[minA].first)->netWorth)
{//如果小根堆的数量已经达到显示数量,但是小根堆的顶部财富小于等于当前遍历的财富值,则压入
q.push(*((ite + j + ageRange[minA].first)));
q.pop();//相应地,弹出一个
}
else if (q.size()<showSum)//如果小根堆还没满,直接压入即可
q.push(*((ite + j + ageRange[minA].first)));
}
vector<PeopleNode> show(min(showSum, (int)q.size()));
for (int j = show.size() – 1; j >= 0; j–)
{//因为需要升序排列,用的是小根堆,所以把小根堆的堆顶放在数组尾部
show[j] = q.top();
q.pop();
}
for (int j = 0; j < show.size(); j++)
{
printf("%s %d %d\n", show[j].name, show[j].age, show[j].netWorth);
}
}
else
{//数量小于等于0,直接输出None
printf("None\n");
sum = 0;
}
}
return 0;
}
[/c]