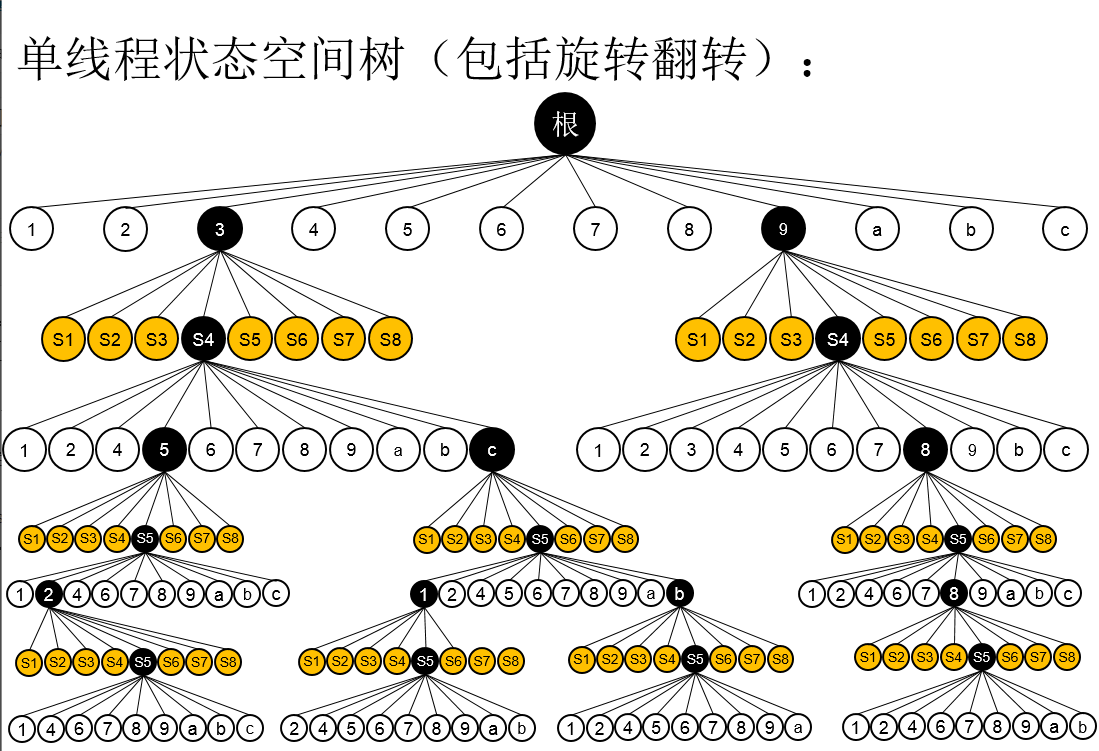
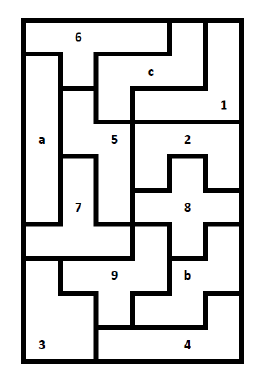
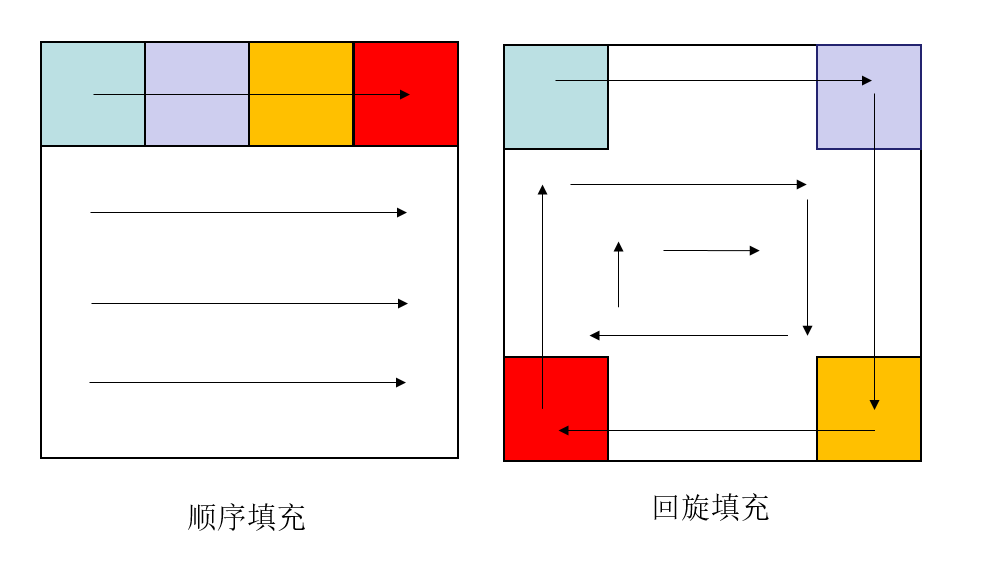
相关文章:
智力拼图问题–关于回溯和并行:单线程到多线程再到GPU编程的进阶(一)
智力拼图问题–关于回溯和并行:单线程到多线程再到GPU编程的进阶(二)
智力拼图问题–关于回溯和并行:单线程到多线程再到GPU编程的进阶(三)
最近需要使用回溯法来完成算法设计的作业,在经历了单线程编程和多线程编程后,发觉效果并不是很理想,于是考虑采用GPU编程,计划通过GPU写一个简单的DFS算法。
本文的目的是快速上手使用GPU和进行简单的编程。首先推荐一本书,在这本书的帮助,我迅速学会了基本的GPU编程。
《CUDA并行程序设计:GPU编程指南》

一、环境配置
1.由于达到快速开发的目的,我直接采用windows平台进行开发,IDE采用的是VS2013.
2.在英伟达的官网上,有CUDA toolkit的下载地址:https://developer.nvidia.com/cuda-downloads
3.CUDA,Compute Unified Device Architecture,是一个运算平台。我们借助这个运算平台去使用GPU进行数据处理。
4.windows版本的安装比较简单,直接在官网下载:
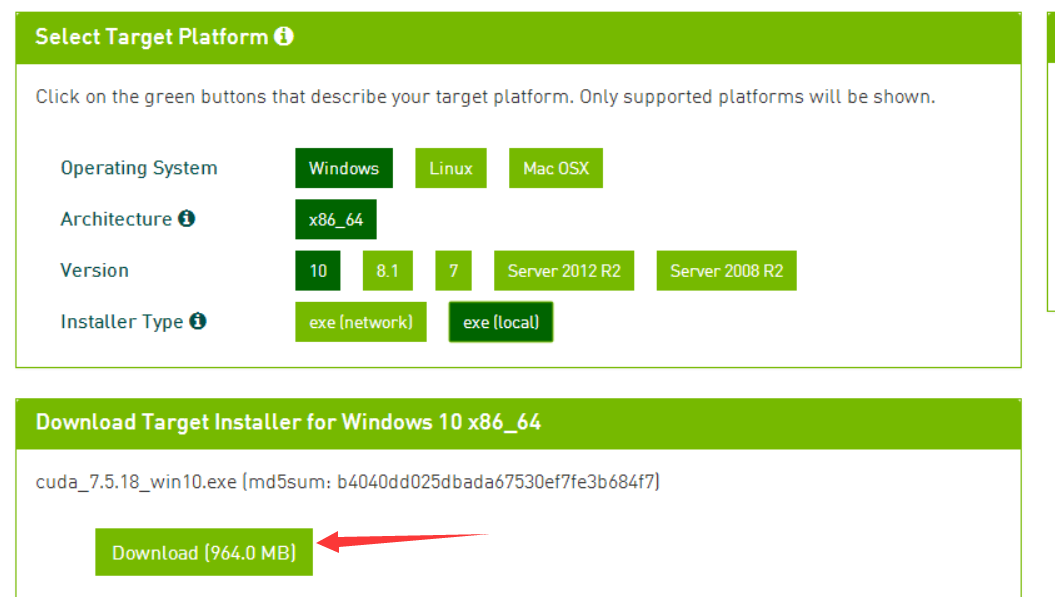
5.接着按照提示安装即可,前提是安装了VS2013或者VS2010\2012。
二、运行例程
安装了一个toolkit后,比较麻烦的事情是配置环境路径,配置项目属性,幸好CUDA提供了一系列的例程,让我们免去了配置的麻烦。CUDA开发者网址:http://docs.nvidia.com/cuda/cuda-samples/index.html
安装完毕后,我们找到CUDA的例程,我的CUDA是安装在C盘:C:\ProgramData\NVIDIA Corporation\,CUDA的例程在C:\ProgramData\NVIDIA Corporation\CUDA Samples\v7.5中,我们可以把例程复制出来,然后打开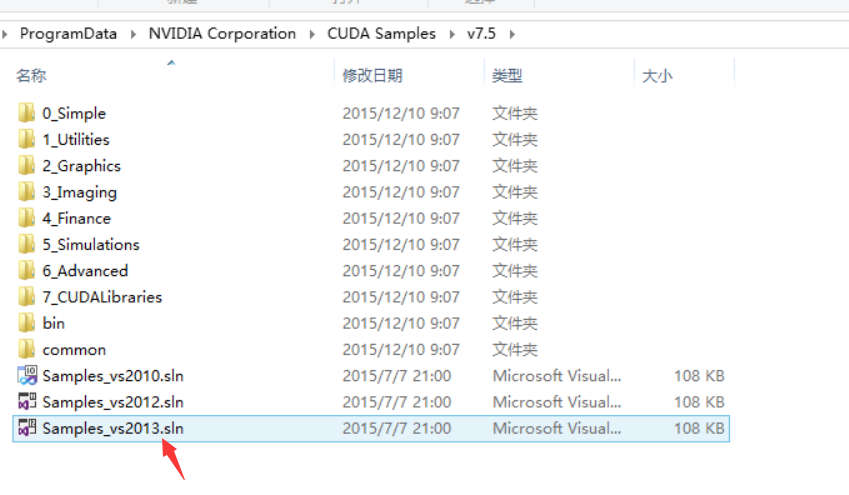
打开后,我们重点关注cppintegration,因为这个例程的划分比较合理,分为main.cpp和cppintegration.cu文件,main.cpp主要是电脑端的代码,cppintegration.cu则主要是设备端的代码。
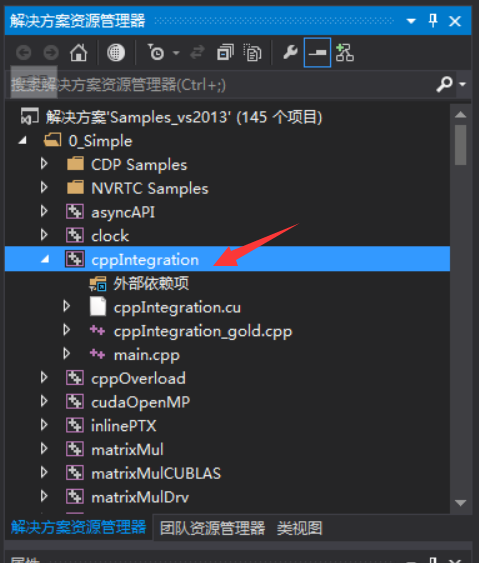
在写代码的时候需要注意,如果我们修改了cppintegration.cu文件里面的代码,那么IDE就会调用CUDA的编译器来进行编译和链接,这个编译链接过程是比较慢的,而只修改main.cpp文件的话,IDE只会重新编译main.cpp,然后重新把.cu生成的文件连接到主程序上,速度会比较快。
[c language=”++”]
// run the device part of the program
bTestResult = runTest(argc, (const char **)argv, str, i2, len);
[/c]
main.cpp代码中,这个代码是调用设备端(即显卡)的函数,我们可以在cppintegration.cu中看到这段代码的定义。
主要的流程如下:
申请显存–>把数据从内存复制到显存–>在显存中进行数据处理–>把数据从显存中复制到内存–>结束
其中,在复制内存的时候也要特别注意,一定需要连续的内存空间!相关文章:
CUDA的内存复制:关于GPU的数据复制问题
CUDA提供了非常丰富的例程中,如有时间,可以选择适合自己的进行研究。而接下来的程序修改,我们都将基于cppintegration项目中的环境。
三、GPU编程特点
(1)基本语法
在GPU编程里面,我们会把函数分为三个类型:__device__、__host__和__global__,对于这三个类型标识符,在关于CUDA里面的global、host、device文章里已经作了解释。
假如我们编写了GPU函数(也称之为内核):
__global__ void runTest() {int a,int b}
那么,如何让GPU来跑这个函数呢?
在调用GPU函数(内核)时,我们需要按照下面的格式:
runTest<<<blocks,threads>>>(a,b)
其中blocks表示需要开启的线程块数量,threads表示每个线程块上开启的线程数。例如:
runTest<<<2,128>>>(a,b)
我们相当于开启了2*128条线程,即并行执行runTest函数256次。
(2)如何标识每一条线程(每一个函数)?
同时开启了256次runTest后,我们如何区分不同线程的runTest?这个时候我们需要使用到blockIdx.x,blockDim.x和threadIdx.x,假设我们运行runTest<<<2,128>>>(a,b)
blockIdx.x表示我们开启的线程块ID,对应上面的程序,blockIdx.x的范围为0到1;
blockDim.x表示每个线程块开启的线程数量,对应上面的程序,blockDim.x为128;
threadIdx.x则表示当前线程在其所在的线程块中的编号。
我们通过const unsigned int tid = (blockIdx.x*blockDim.x) + threadIdx.x;就可以得到线程的id号,而接下来的编程,我们会把线程的id作为数组的下标,从而实现并行计算。
四、编程实践
有了上述的初步理解后,我们就可以进行GPU编程,我们来做一个简单的实现,计算数组a和数组b下标相同的对应元素的积,并存放到数组c中,即c[i]=a[i]*b[i],然后再使用for循环使c[i]++ 10240次。
可能你们会想到,这使用for循环不是很容易解决吗?好的,为了凸显显卡强大的并行计算能力,我们把数组a和数组b的长度定义为1024*1024(略超过100万)。下面我们进行编程实现:
简单的for循环实现:
[c language=”++”]
void multipleCPU(int *const a_gpu, int *const b_gpu, int *const c_gpu)
{
for (int i = 0; i <1024*1024; i++)
{
c_gpu[i] = a_gpu[i] * b_gpu[i];
for (int j = 0; j <10240; j++)
c_gpu[i]++;
}
}
[/c]
而GPU编程,我们把计算放在内核中,开启1024个线程块,每个线程块开启1024条线程,即总共开启1024*1024(100万)条线程进行数据处理,显卡处理100万条线程还是十分轻松的。
需要注意的是,目前大部分英伟达显卡,单个线程块支持的最大线程数是1024条,我们可以通过打印显卡的信息获得相关信息:
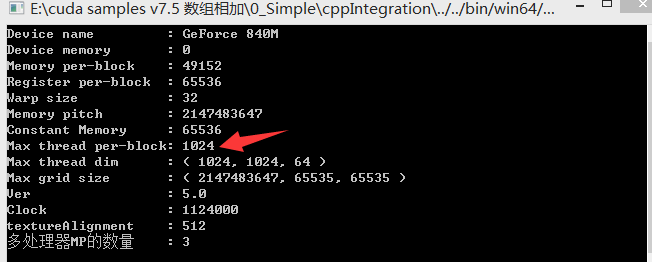
下面是GPU的内核实现和接口调用代码:
[c language=”++”]
/*
函数名 :gpuTestSiukwan
函数功能:计算a_gpu[i] * b_gpu[i],并把结果存放到c_gpu[i]中,
输入参数:
a_gpu :被填充的矩阵
b_gpu :用来填充的图形
c_gpu :被填充矩阵的第一个空格位置x
*/
__global__ void gpuTestSiukwan(int *const a_gpu, int *const b_gpu, int *const c_gpu)
{
// write data to global memory
const unsigned int tid = (blockIdx.x*blockDim.x) + threadIdx.x;
c_gpu[tid] = a_gpu[tid] * b_gpu[tid];
for (int i = 0; i <10240; i++)
c_gpu[tid]++;
}
//接口函数
extern "C" void runCUDA_AddOne(int blocks, int threads, int *const a_gpu, int *const b_gpu, int *const c_gpu)
{
gpuTestSiukwanAddOne<<<blocks, threads >>>(a_gpu, b_gpu, c_gpu);
}
[/c]
当然,还有基本的数据转移操作 ,从内存复制到显存,再从显存复制到内存:
[c language=”++”]
//定义gpu上的变量
int *a_gpu, *b_gpu, *c_gpu;
//在gpu上分配内存
cudaMalloc((void **)&amp;a_gpu, sizeof(int) * 1024);
cudaMalloc((void **)&amp;b_gpu, sizeof(int) * 1024);
cudaMalloc((void **)&amp;c_gpu, sizeof(int) * 1024);
//把数据从内存复制到显存
cudaMemcpy(a_gpu, a_cpu, sizeof(int) * 1024, cudaMemcpyHostToDevice);
cudaMemcpy(b_gpu, b_cpu, sizeof(int) * 1024, cudaMemcpyHostToDevice);
//////////////////////////////////////////////////////
//CUDA运算
//////////////////////////////////////////////////////
runCUDA(blocks, threads,a_gpu, b_gpu, c_gpu);
//把在gpu中处理完毕的数据从显存复制到内存
cudaMemcpy(c_cpu, c_gpu, sizeof(int) * 1024, cudaMemcpyDeviceToHost);
//释放相关变量的显存
cudaFree(a_gpu);
cudaFree(b_gpu);
cudaFree(c_gpu);
[/c]
详细的代码,已经放到github上:https://github.com/siukwan/algorithm
大家可以上去下载下来,运行一下。
实验数据如下,可以看到单纯使用GPU运算,耗时45秒,而使用GPU运算,基本在1秒内:
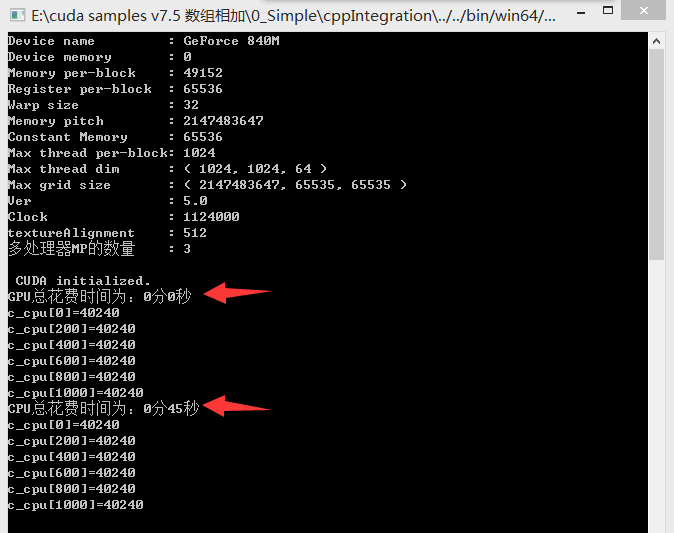
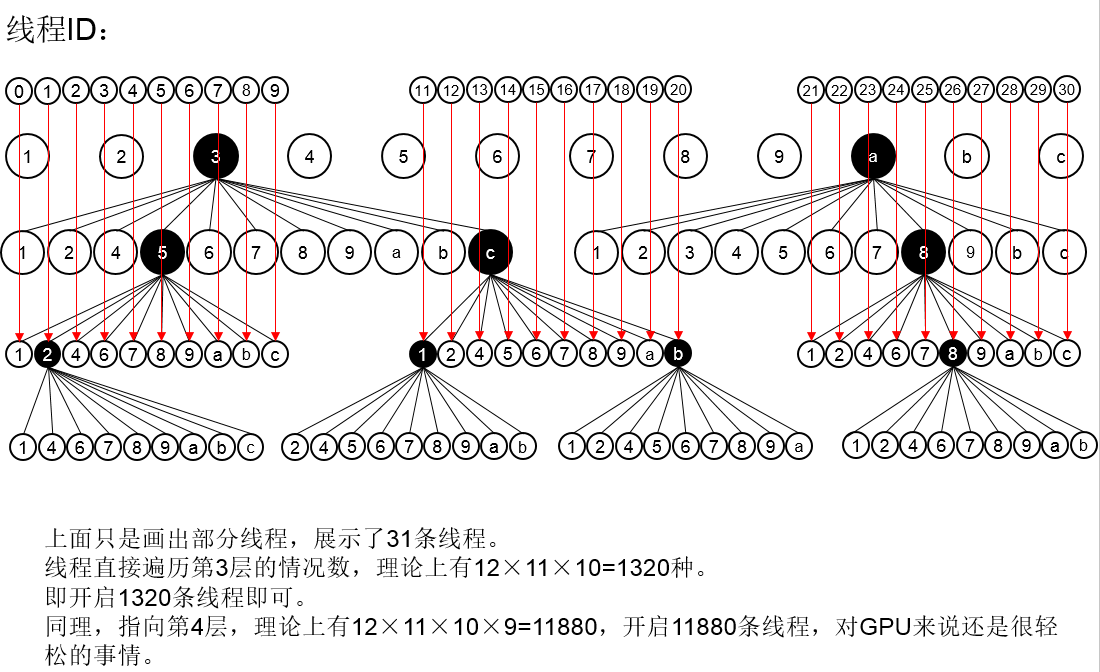
当然,GPU的每个线程并不能进行十分复杂的操作,例如我进行多次递归操作后,GPU驱动会崩溃,所以在设计算法的时候要注意这一点:
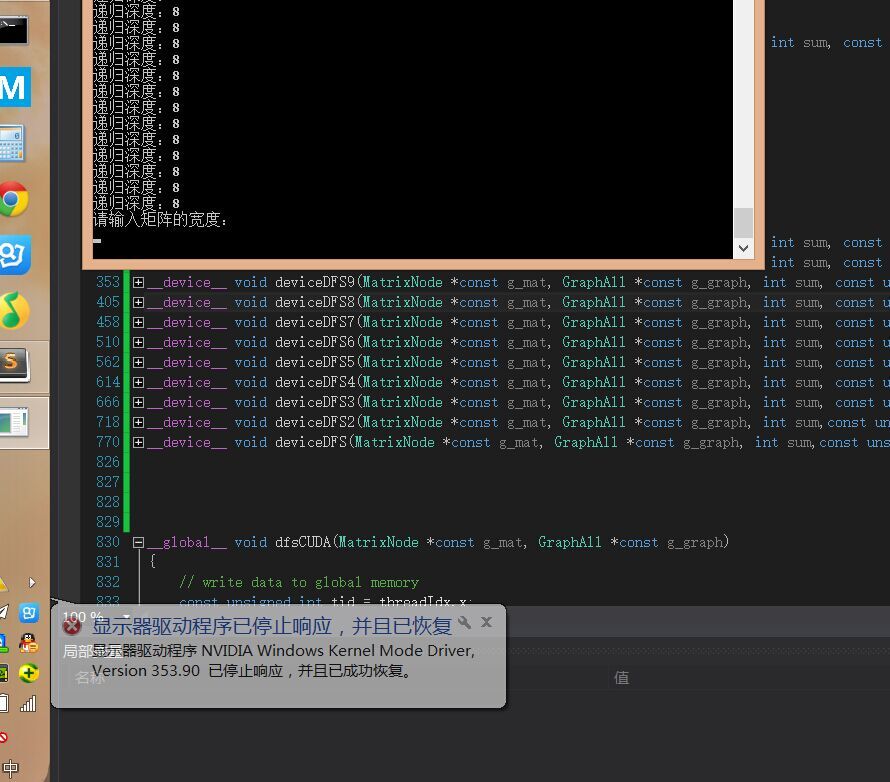
五、GPU编程进阶
当初使用学习GPU编程,是为了完成算法设计的作业,相关文章如下:
相关文章:
智力拼图问题–关于回溯和并行:单线到多线程再到GPU编程的进阶(三)
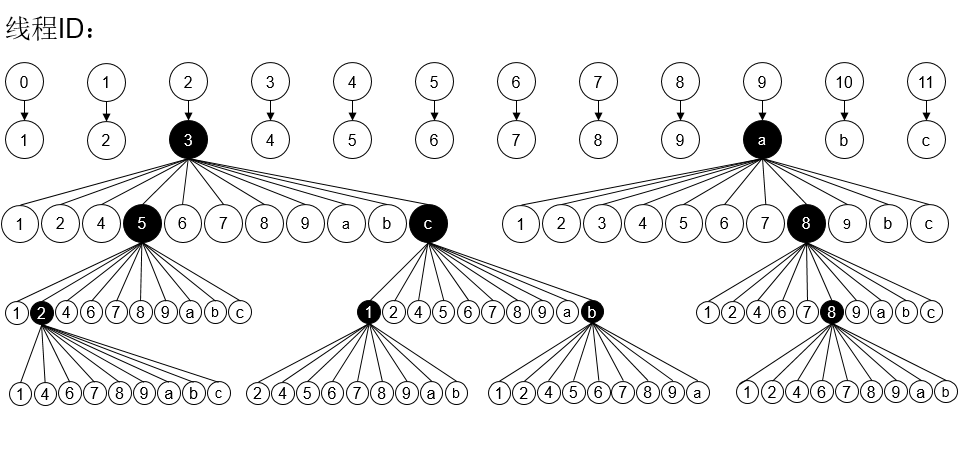
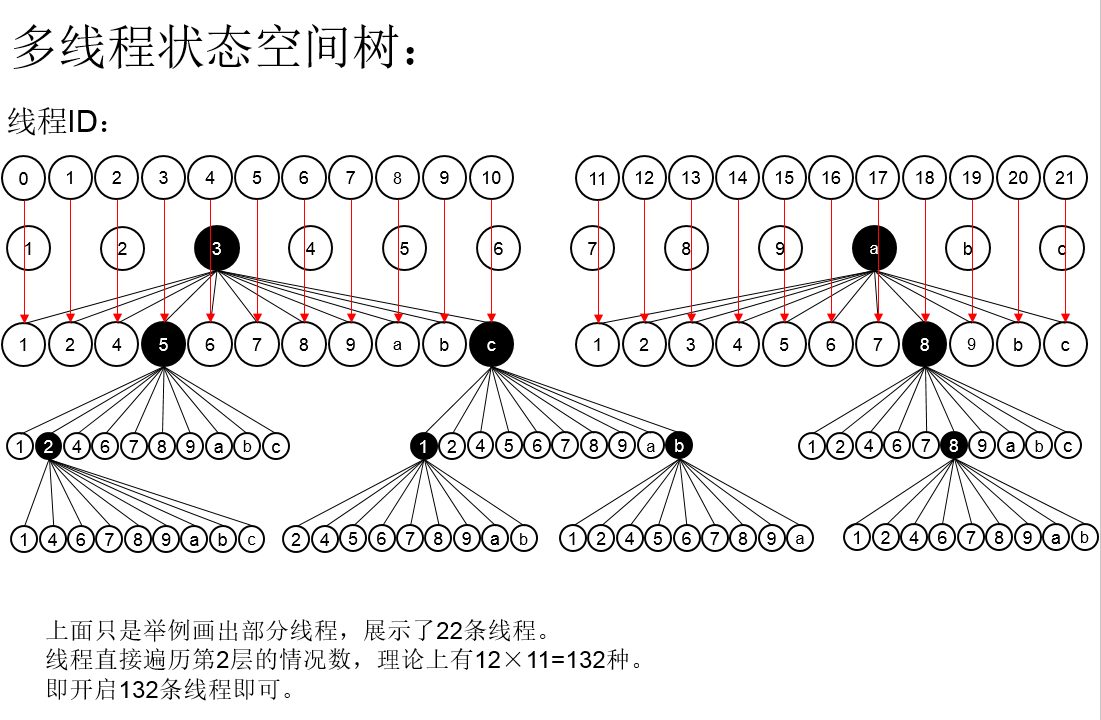
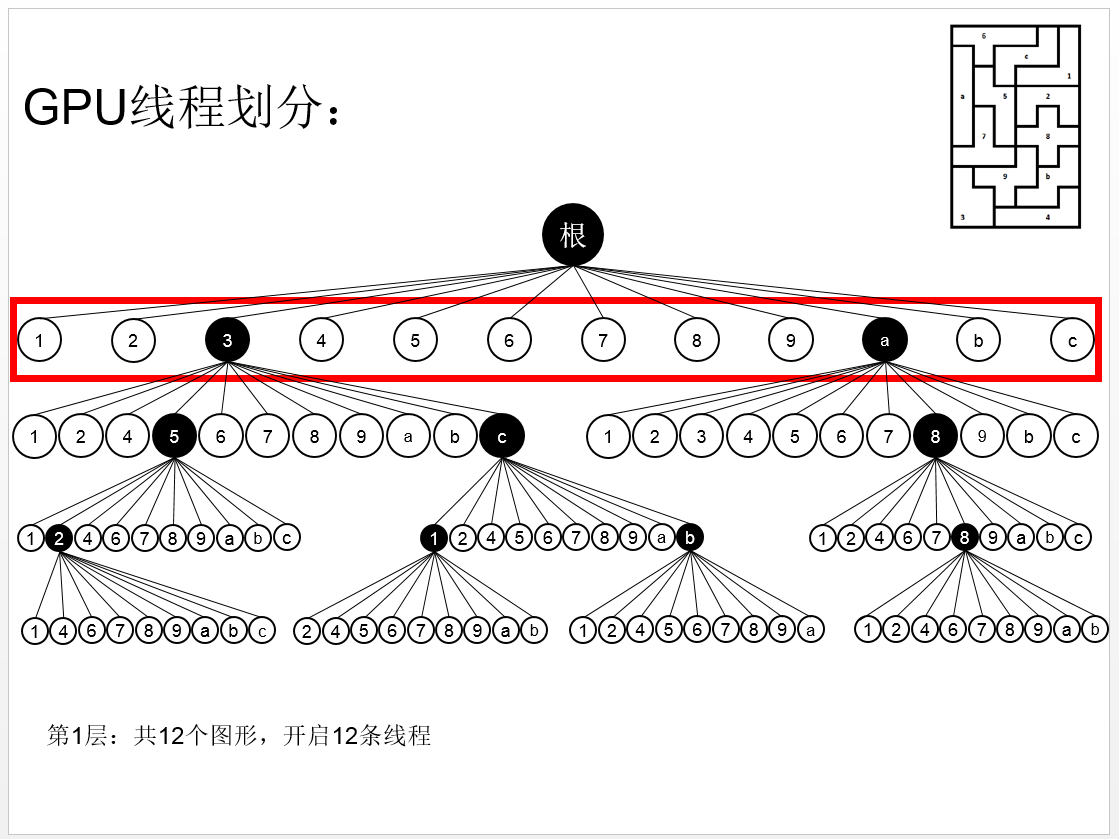
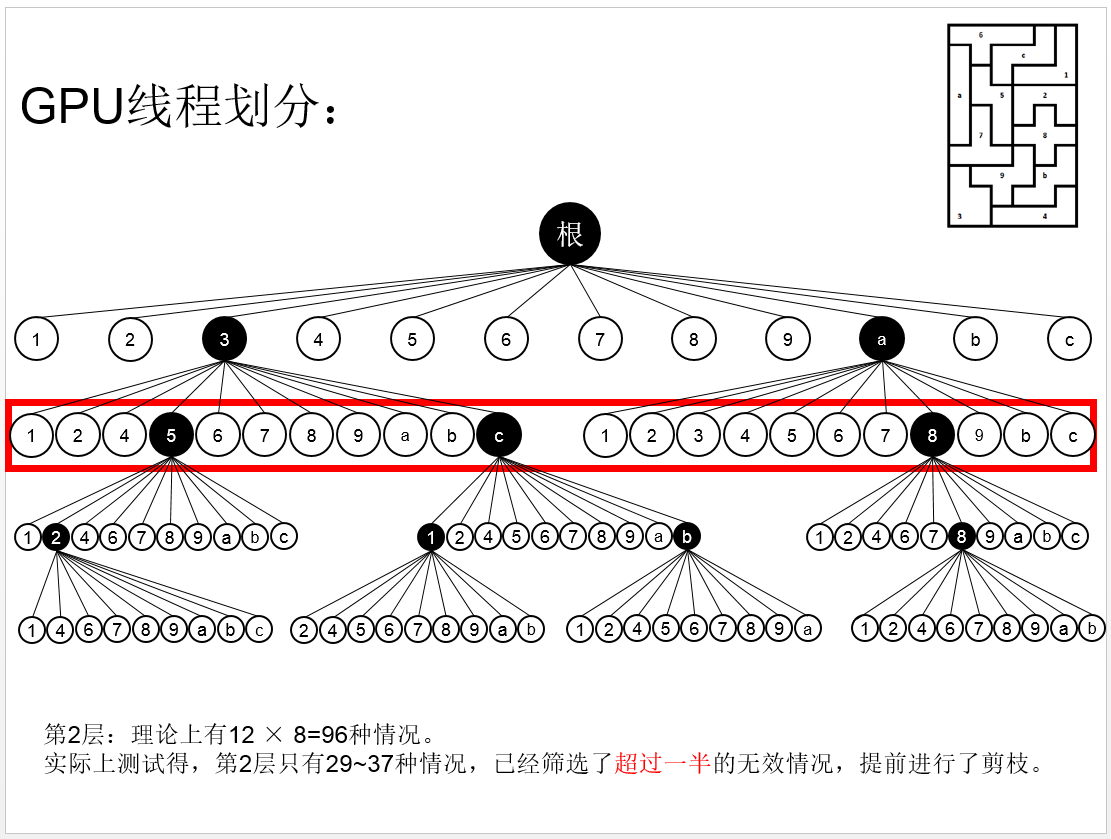
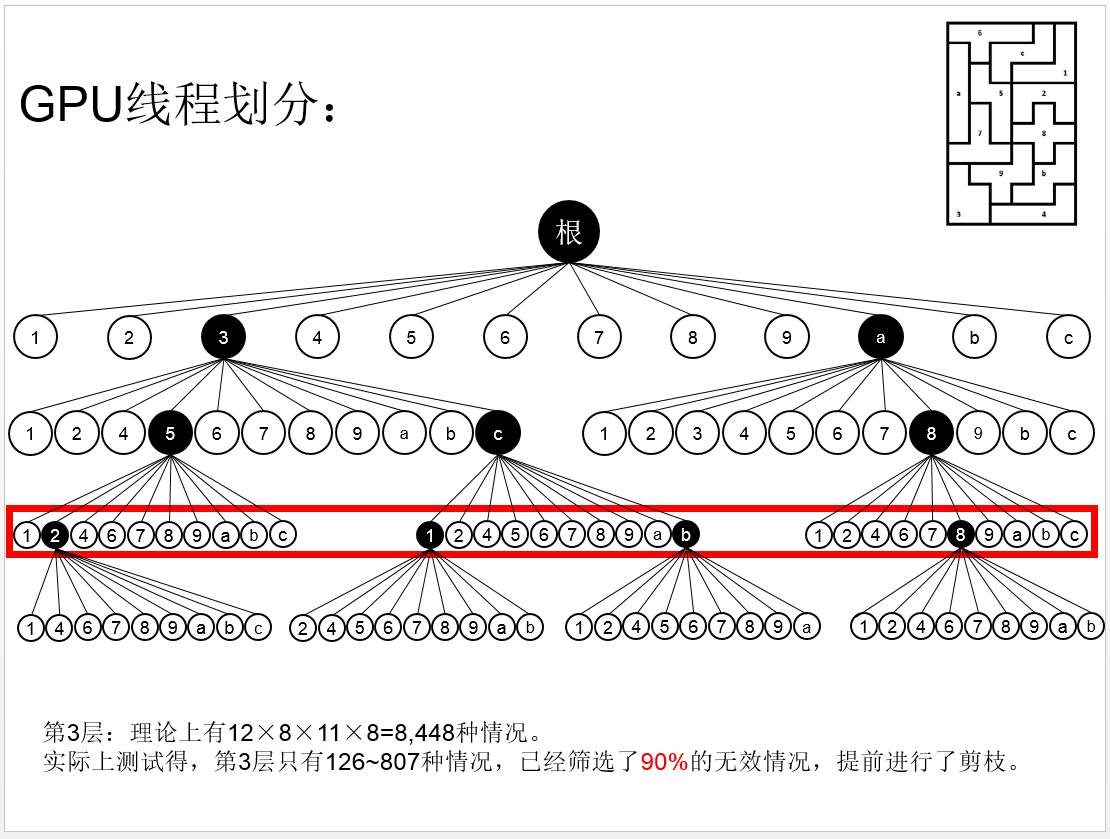
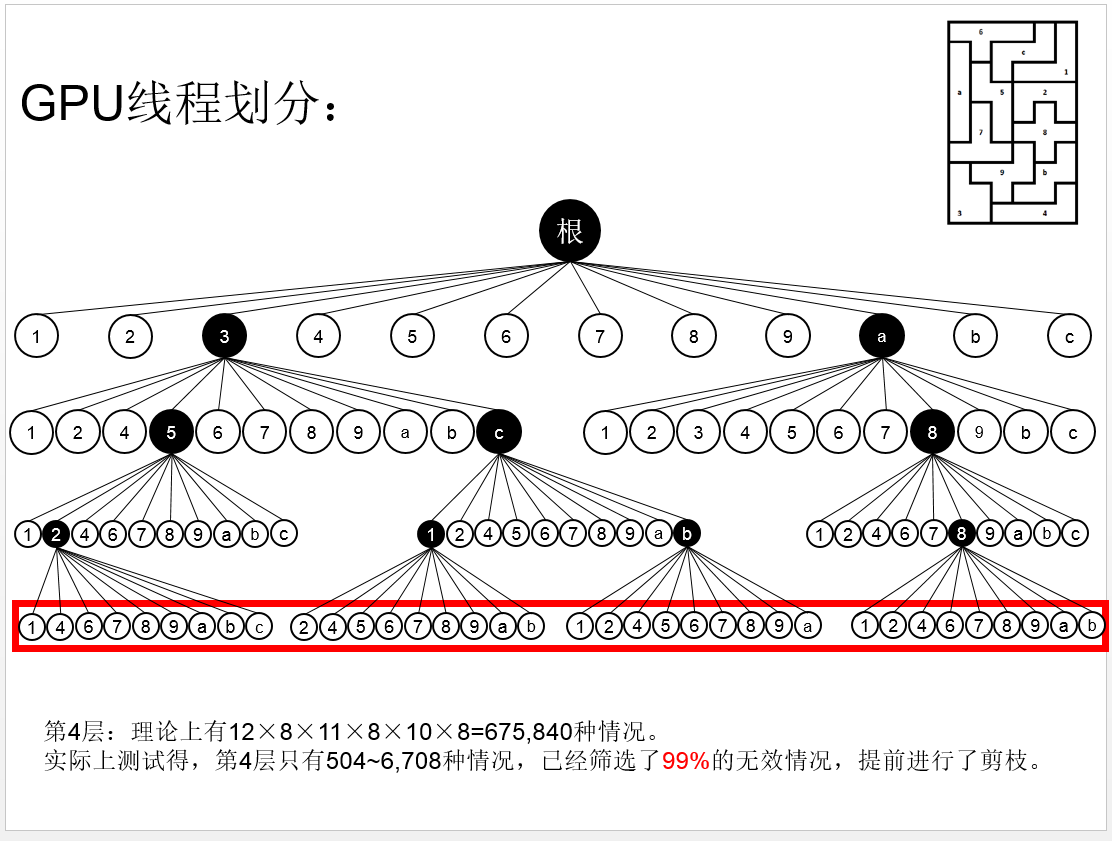
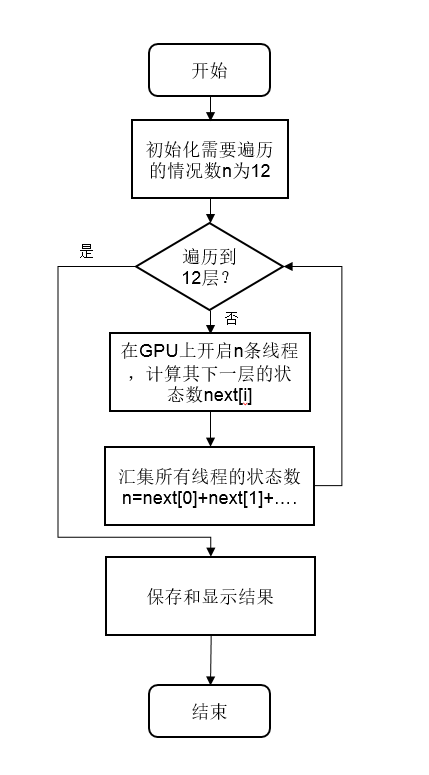
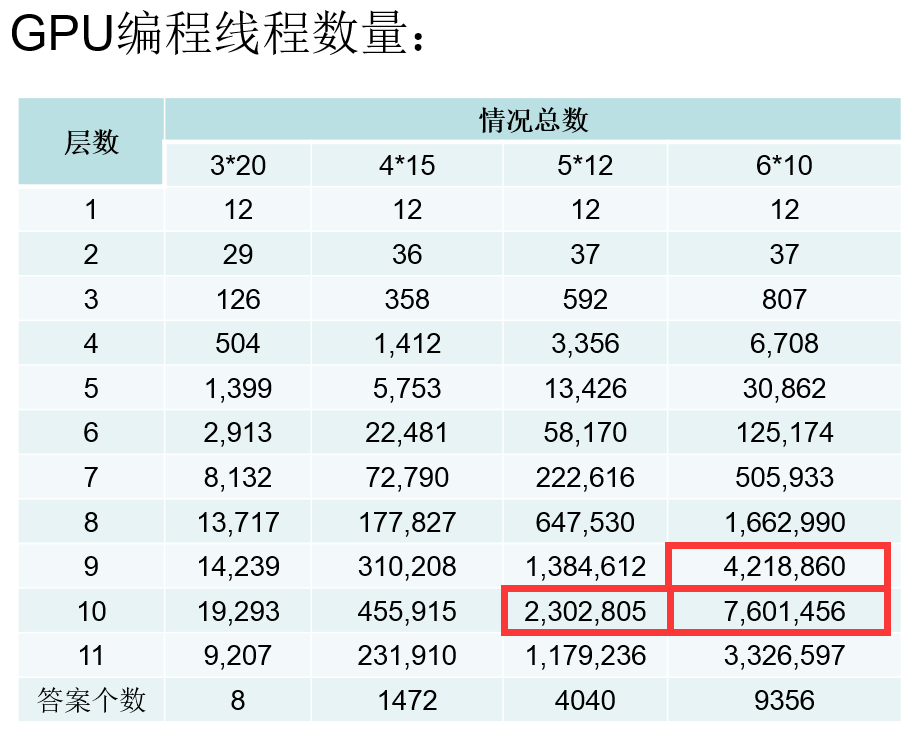
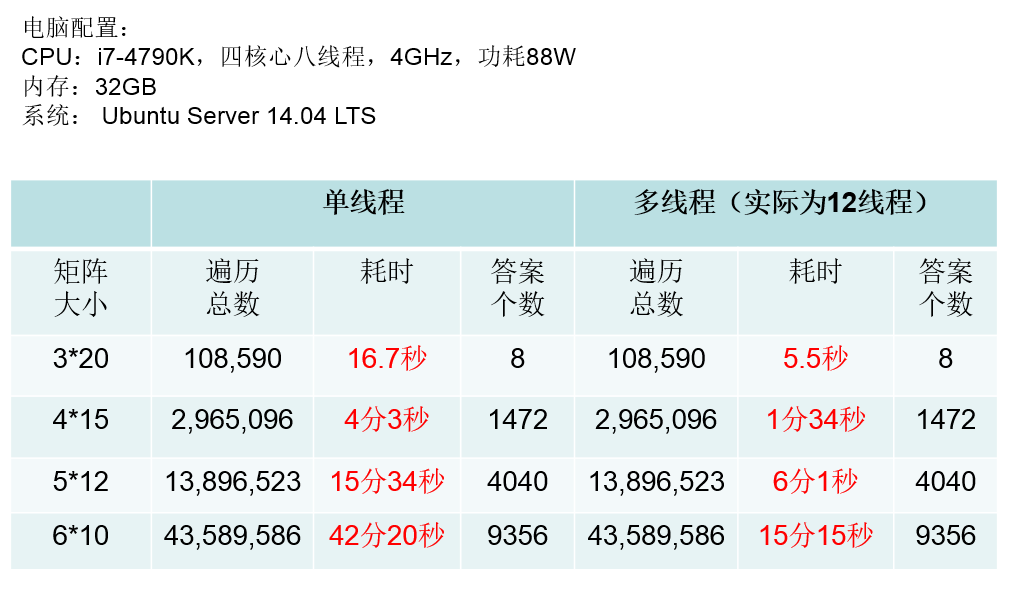
这道题目还是十分有意思的,而实验结果也是十分惊人的,下面为在对这道题目进行实验室得出的部分实验数据对比举例:

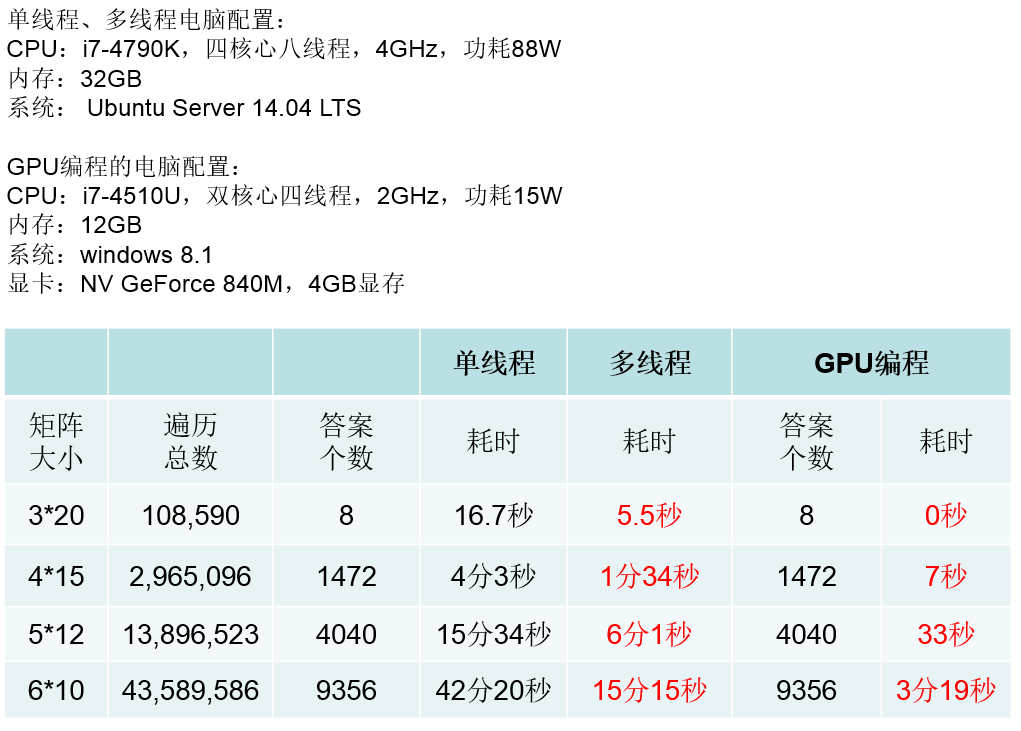
目前英伟达在官网上面提供了很多工具包,也就是说不需要亲自写这么底层的代码,对指针进行操作,对数据进行从内存到显存的复制和从显存到内存的复制。CUDA在深度学习、图像处理、大数据分析等等方面都有极为重要的应用,我们应该充分发挥英伟达显卡的性能。有兴趣的童鞋可以浏览CUDA的网址进一步了解:https://developer.nvidia.com/cuda-zone