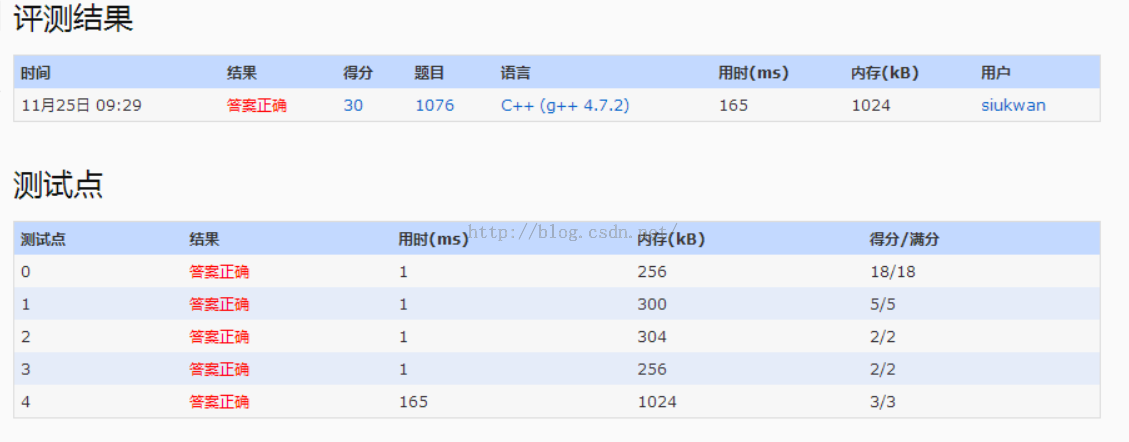
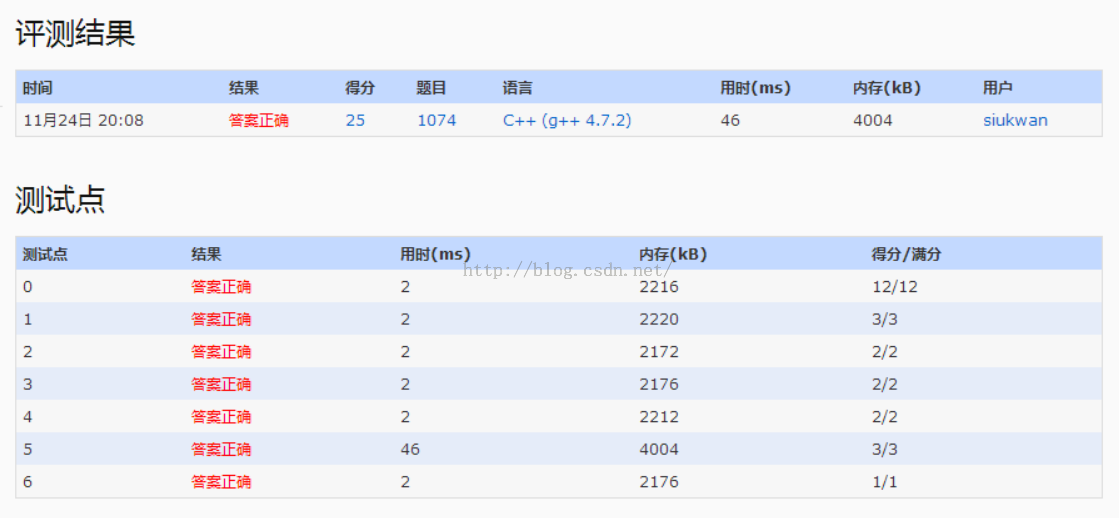
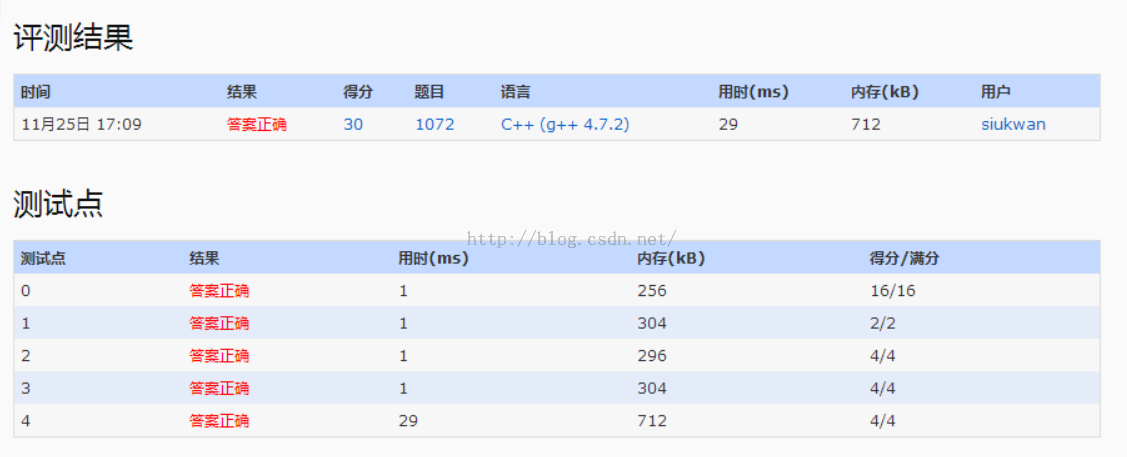
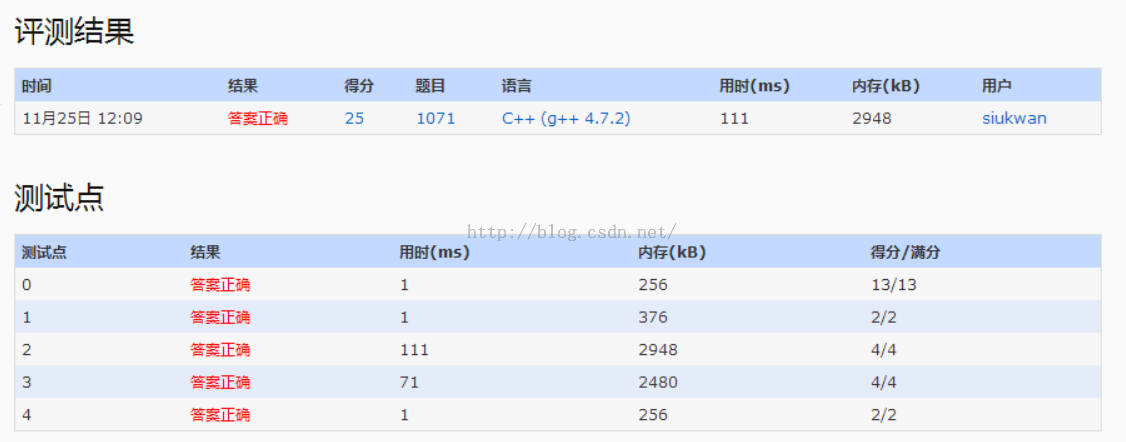
1.题目给出一些供应商和零售商,其中零售商处于供应链的多个级别,每个级别的售价都需要乘以一个系数,最后求出总售价。
2.使用树的结构存储供应商和零售商。
3.采用层次遍历(BFS)进行遍。
4.需要使用double进行存储,一开始发现下面几个耗时大的测试点不通过,所以考虑是精度不够或者溢出的原因,于是改为double类型,然后就通过了。

A supply chain is a network of retailers(零售商), distributors(经销商), and suppliers(供应商)– everyone involved in moving a product from supplier to customer.
Starting from one root supplier, everyone on the chain buys products from one’s supplier in a price P and sell or distribute them in a price that is r% higher than P. Only the retailers will face the customers. It is assumed that each member in the supply chain has exactly one supplier except the root supplier, and there is no supply cycle.
Now given a supply chain, you are supposed to tell the total sales from all the retailers.
Input Specification:
Each input file contains one test case. For each case, the first line contains three positive numbers: N (<=105), the total number of the members in the supply chain (and hence their ID’s are numbered from 0 to N-1, and the root supplier’s ID is 0); P, the unit price given by the root supplier; and r, the percentage rate of price increment for each distributor or retailer. Then N lines follow, each describes a distributor or retailer in the following format:
Ki ID[1] ID[2] … ID[Ki]
where in the i-th line, Ki is the total number of distributors or retailers who receive products from supplier i, and is then followed by the ID’s of these distributors or retailers. Kj being 0 means that the j-th member is a retailer, then instead the total amount of the product will be given after Kj. All the numbers in a line are separated by a space.
Output Specification:
For each test case, print in one line the total sales we can expect from all the retailers, accurate up to 1 decimal place. It is guaranteed that the number will not exceed 1010.
Sample Input:
10 1.80 1.00 3 2 3 5 1 9 1 4 1 7 0 7 2 6 1 1 8 0 9 0 4 0 3
Sample Output:
42.4
AC代码:
[c language=”++”]
//#include<string>
//#include <iomanip>
//#include<stack>
//#include<unordered_set>
//#include <sstream>
//#include "func.h"
//#include <list>
#include<unordered_map>
#include<set>
#include<queue>
#include<map>
#include<vector>
#include <algorithm>
#include<stdio.h>
#include<iostream>
#include<string>
#include<memory.h>
#include<limits.h>
#include<stack>
using namespace std;
struct Node{
vector<int> list;
bool isRetailer;
int productCount;
Node() :list(0), isRetailer(false), productCount(0){};
};
int main(void)
{
int n;
double rootPrice, higher;//需要使用double
cin >> n >> rootPrice >> higher;
vector<Node> chain(n);
for (int i = 0; i < n; i++)
{
int tmp;
cin >> tmp;
if (tmp == 0)
{//零售商
chain[i].isRetailer = true;
cin >> chain[i].productCount;
}
else
{//供应商
for (int j = 0; j < tmp; j++)
{//输入下级供应商
int nextLevel;
cin >> nextLevel;
chain[i].list.push_back(nextLevel);
}
}
}
queue<int> q;
q.push(0);
int count1 = 1, count2 = 0;
double price = rootPrice;
double totalSales = 0;
//进行层次遍历
while (!q.empty())
{
for (int i = 0; i < count1; i++)
{
int head = q.front(); q.pop();
if (chain[head].isRetailer)
totalSales += chain[head].productCount*price;
else
{
for (int j = 0; j < chain[head].list.size(); j++)
{
q.push(chain[head].list[j]);
count2++;
}
}
}
count1 = count2;
count2 = 0;
price *= (1 + higher / 100.0);
}
printf("%.1lf\n", totalSales);
return 0;
}
[/c]