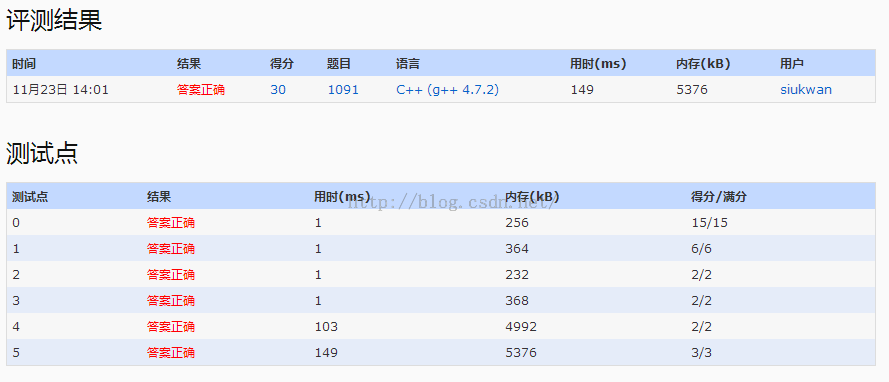
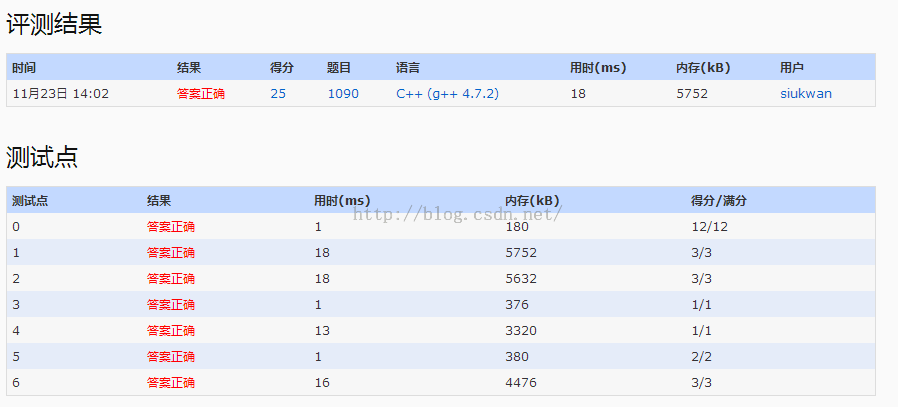
1.题目要求给出目标串和原串,求种类差异和数目差异。
2.使用哈希表分别记录两串的bead数量
3.需要使用迭代器进行遍历,避免出现重复情况:
如ppRYYGrrYBR2258和YrR8RrY,用YrR8RrY来遍历,则前面遍历了R,后面又遍历了R,导致统计的重复。
Eva would like to make a string of beads with her favorite colors so she went to a small shop to buy some beads. There were many colorful strings of beads. However the owner of the shop would only sell the strings in whole pieces. Hence Eva must check whether a string in the shop contains all the beads she needs. She now comes to you for help: if the answer is “Yes”, please tell her the number of extra beads she has to buy; or if the answer is “No”, please tell her the number of beads missing from the string.
For the sake of simplicity, let’s use the characters in the ranges [0-9], [a-z], and [A-Z] to represent the colors. For example, the 3rd string in Figure 1 is the one that Eva would like to make. Then the 1st string is okay since it contains all the necessary beads with 8 extra ones; yet the 2nd one is not since there is no black bead and one less red bead.
 Figure 1
Figure 1Each input file contains one test case. Each case gives in two lines the strings of no more than 1000 beads which belong to the shop owner and Eva, respectively.
Output Specification:
For each test case, print your answer in one line. If the answer is “Yes”, then also output the number of extra beads Eva has to buy; or if the answer is “No”, then also output the number of beads missing from the string. There must be exactly 1 space between the answer and the number.
Sample Input 1:
ppRYYGrrYBR2258 YrR8RrY
Sample Output 1:
Yes 8
Sample Input 2:
ppRYYGrrYB225 YrR8RrY
Sample Output 1:
No 2
AC代码:
[c language=”++”]
//#include<string>
//#include <iomanip>
#include<vector>
#include <algorithm>
//#include<stack>
#include<set>
#include<queue>
#include<map>
//#include<unordered_set>
#include<unordered_map>
//#include <sstream>
//#include "func.h"
//#include <list>
#include<stdio.h>
#include<iostream>
#include<string>
#include<memory.h>
#include<limits.h>
using namespace std;
int main(void)
{
string give, favourite;
cin >> give >> favourite;
map<char, int> giveCount;
map<char, int> fCount;
for (int i = 0; i < give.size(); i++)
{
giveCount[give[i]]++;
}
for (int i = 0; i < favourite.size(); i++)
{
fCount[favourite[i]]++;
}
int more = 0;
int less = 0;
bool satify = true;
for (map<char, int>::iterator ite = fCount.begin(); ite != fCount.end();ite++)
{//需要使用迭代器进行遍历,避免出现重复情况
/*
如ppRYYGrrYBR2258和YrR8RrY,用YrR8RrY来遍历,则前面遍历了R,后面又遍历了R,导致统计的重复
*/
int bead = ite->first;
if (satify && fCount[bead] <= giveCount[bead])
more += giveCount[bead] – fCount[bead];
else
{
satify = false;
if (fCount[bead] > giveCount[bead])
less += fCount[bead] – giveCount[bead];
}
}
if (satify)
{
cout << "Yes " << give.size() – favourite.size() << endl;
}
else
cout << "No " << less << endl;
return 0;
}
[/c]