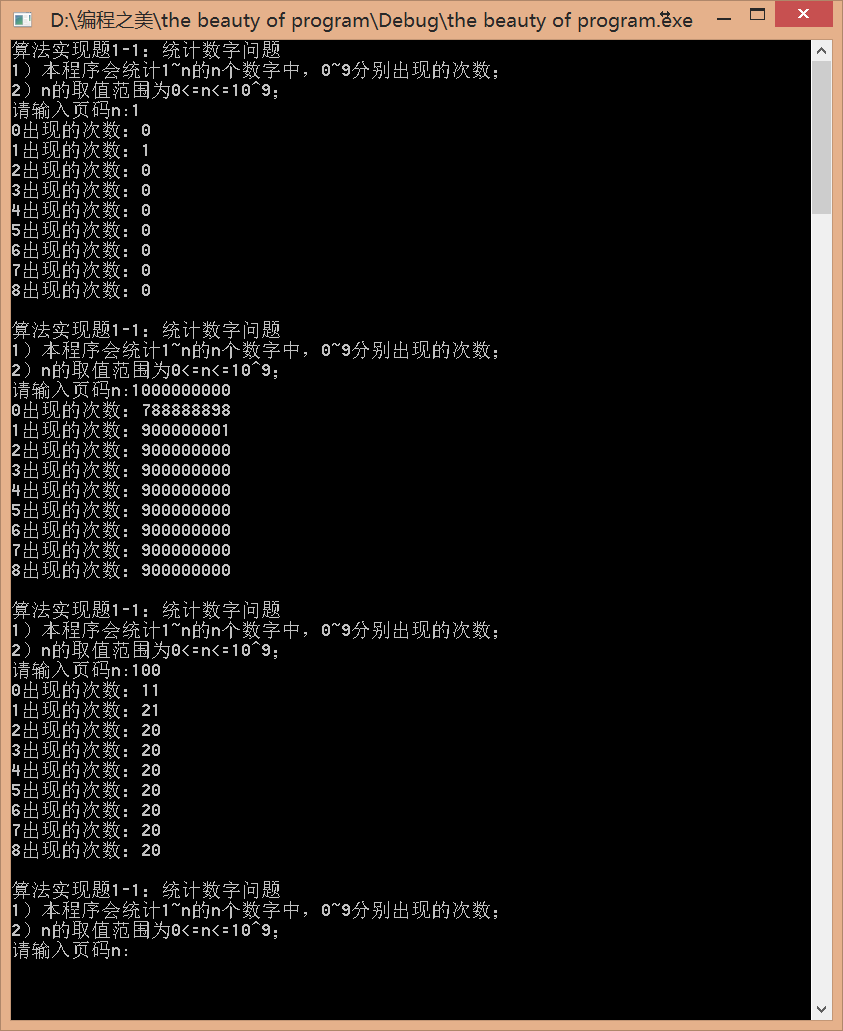
1.题目给出一个前序遍历的数组,要求判断是否是BST或者是镜像的BST,如果是,则输出它的层次遍历。
2.写两个函数,分别用来建立正常的BST:dfs和镜像BST:dfsMirror。这样就不用在检查的时候进行判断。
3.如果使用dfs不能建立BST,那么使用dfsMirror进行建立,两者都不能建立,则输出NO。
A Binary Search Tree (BST) is recursively defined as a binary tree which has the following properties:
- The left subtree of a node contains only nodes with keys less than the node’s key.
- The right subtree of a node contains only nodes with keys greater than or equal to the node’s key.
- Both the left and right subtrees must also be binary search trees.
If we swap the left and right subtrees of every node, then the resulting tree is called the Mirror Image of a BST.
Now given a sequence of integer keys, you are supposed to tell if it is the preorder traversal sequence of a BST or the mirror image of a BST.
Input Specification:
Each input file contains one test case. For each case, the first line contains a positive integer N (<=1000). Then N integer keys are given in the next line. All the numbers in a line are separated by a space.
Output Specification:
For each test case, first print in a line “YES” if the sequence is the preorder traversal sequence of a BST or the mirror image of a BST, or “NO” if not. Then if the answer is “YES”, print in the next line the postorder traversal sequence of that tree. All the numbers in a line must be separated by a space, and there must be no extra space at the end of the line.
Sample Input 1:
7 8 6 5 7 10 8 11
Sample Output 1:
YES 5 7 6 8 11 10 8
Sample Input 2:
7 8 10 11 8 6 7 5
Sample Output 2:
YES 11 8 10 7 5 6 8
Sample Input 3:
7 8 6 8 5 10 9 11
Sample Output 3:
NO
AC代码:
[c language=”++”]
//#include<string>
//#include <iomanip>
#include<vector>
#include <algorithm>
//#include<stack>
#include<set>
#include<queue>
#include<map>
//#include<unordered_set>
#include<unordered_map>
//#include <sstream>
//#include "func.h"
//#include <list>
#include<stdio.h>
#include<iostream>
#include<string>
#include<memory.h>
#include<limits.h>
using namespace std;
struct TreeNode{
int val;
TreeNode *l, *r;
TreeNode(int x) :val(x), l(NULL), r(NULL){};
TreeNode() :val(-1), l(NULL), r(NULL){};
};
TreeNode*dfs(vector<int>&node, int l, int r, bool&buildSuccess)
{//建立正常的BST
if (l>r) return NULL;
else if (l == r)
{
return new TreeNode(node[l]);
}
else
{
TreeNode* root = new TreeNode(node[l]);
int i = l + 1;
while (i <= r&&node[i]<root->val)
{
i++;
}
int j = i;
while (j <= r&&node[j] >= root->val)
{
j++;
}
if (i != r + 1 && j != r + 1)
{//如果i没有达到最终点且j也没有到达最终点,证明数组里面有部分点不满足要求,所以不能构建
buildSuccess = false;
return NULL;
}
root->l = dfs(node, l + 1, i – 1, buildSuccess);
root->r = dfs(node, i, r, buildSuccess);
return root;
}
}
TreeNode*dfsMirror(vector<int>&node, int l, int r, bool&buildSuccess)
{//基本同上
if (l>r) return NULL;
else if (l == r)
{
return new TreeNode(node[l]);
}
else
{
TreeNode* root = new TreeNode(node[l]);
int i = l + 1;
while (i <= r&&node[i] >= root->val)
{
i++;
}
int j = i;
while (j <= r&&node[j]<root->val)
{
j++;
}
if (i != r + 1 && j != r + 1)
{
buildSuccess = false;
return NULL;
}
root->l = dfsMirror(node, l + 1, i – 1, buildSuccess);
root->r = dfsMirror(node, i, r, buildSuccess);
return root;
}
}
void postOrderDFS(TreeNode*root, vector<int>&postOrder)
{
if (root != NULL)
{
postOrderDFS(root->l, postOrder);
postOrderDFS(root->r, postOrder);
postOrder.push_back(root->val);
}
}
/*
7 8 6 5 7 10 8 11
7 8 10 11 8 6 7 5
7 8 6 8 5 10 9 11
*/
int main(void)
{
int nodeSum;
cin >> nodeSum;
vector<int> node(nodeSum);
for (int i = 0; i<nodeSum; i++)
{
scanf("%d", &node[i]);
}
bool buildSuccess = true;
TreeNode*tree = dfs(node, 0, (int)(node.size() – 1), buildSuccess);
if (!buildSuccess)
{
buildSuccess = true;
tree = dfsMirror(node, 0, (int)(node.size() – 1), buildSuccess);
}
if (buildSuccess)
{
cout << "YES" << endl;
vector<int> postOrder(0);
postOrderDFS(tree, postOrder);
for (int i = 0; i<postOrder.size(); i++)
{
cout << postOrder[i];
if (i != postOrder.size() – 1)
cout << " ";
}
cout << endl;
}
else
cout << "NO" << endl;
return 0;
}
[/c]
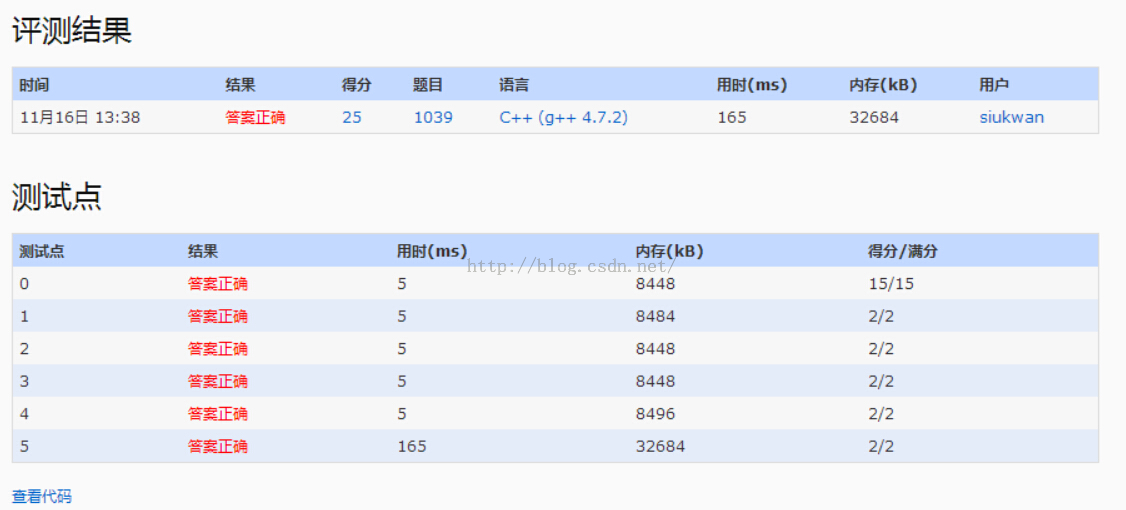
 因为相亲总是在男女之间进行的,所以每一条边的两边对应的人总是不同性别。假设表示男性的节点染成白色,女性的节点染色黑色。对于得到的无向图来说,即每一条边的两端一定是一白一黑。如果存在一条边两端同为白色或者黑色,则表示这一条边所表示的记录有误。
因为相亲总是在男女之间进行的,所以每一条边的两边对应的人总是不同性别。假设表示男性的节点染成白色,女性的节点染色黑色。对于得到的无向图来说,即每一条边的两端一定是一白一黑。如果存在一条边两端同为白色或者黑色,则表示这一条边所表示的记录有误。 在染色的过程中,我们应该怎样发现错误的记录呢?相信你一定发现了吧。对于一个已经染色的点,如果存在一个与它相邻的已染色点和它的颜色相同,那么就一定存在一条错误的记录。(如上图的4,5节点)
在染色的过程中,我们应该怎样发现错误的记录呢?相信你一定发现了吧。对于一个已经染色的点,如果存在一个与它相邻的已染色点和它的颜色相同,那么就一定存在一条错误的记录。(如上图的4,5节点)