1.题目的要求是,每次选取NG个用户组成一组进行比赛,第一名进入下一轮,其他落败的用户排名相同。
2.刚开始卡在了这里,误以为在最后议论的比赛中,用户要排1,2,3,4。。结果不是,最后一轮,胜出的排第一名,落败的均为第二名。
3.排名的统计,假如这次有N个group,那么这次落败的用户排名为N+1。
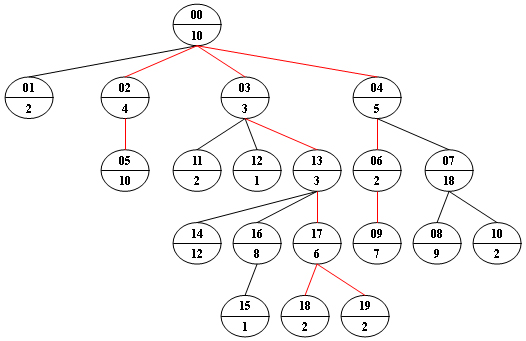
4.第三个数组是用户次序,如6 0 8 7 10 5 9 1 4 2 3
则分组为:
6 0 8
7 10 5
9 1 4
2 3
共四个组
Mice and Rice is the name of a programming contest in which each programmer must write a piece of code to control the movements of a mouse in a given map. The goal of each mouse is to eat as much rice as possible in order to become a FatMouse.
First the playing order is randomly decided for NP programmers. Then every NG programmers are grouped in a match. The fattest mouse in a group wins and enters the next turn. All the losers in this turn are ranked the same. Every NGwinners are then grouped in the next match until a final winner is determined.
For the sake of simplicity, assume that the weight of each mouse is fixed once the programmer submits his/her code. Given the weights of all the mice and the initial playing order, you are supposed to output the ranks for the programmers.
Input Specification:
Each input file contains one test case. For each case, the first line contains 2 positive integers: NP and NG (<= 1000), the number of programmers and the maximum number of mice in a group, respectively. If there are less than NG mice at the end of the player’s list, then all the mice left will be put into the last group. The second line contains NP distinct non-negative numbers Wi (i=0,…NP-1) where each Wiis the weight of the i-th mouse respectively. The third line gives the initial playing order which is a permutation of 0,…NP-1 (assume that the programmers are numbered from 0 to NP-1). All the numbers in a line are separated by a space.
Output Specification:
For each test case, print the final ranks in a line. The i-th number is the rank of the i-th programmer, and all the numbers must be separated by a space, with no extra space at the end of the line.
Sample Input:
11 3 25 18 0 46 37 3 19 22 57 56 10 6 0 8 7 10 5 9 1 4 2 3
Sample Output:
5 5 5 2 5 5 5 3 1 3 5
AC代码:
[c language=”++”]
//#include<string>
//#include<stack>
//#include<unordered_set>
//#include <sstream>
//#include "func.h"
//#include <list>
#include <iomanip>
#include<unordered_map>
#include<set>
#include<queue>
#include<map>
#include<vector>
#include <algorithm>
#include<stdio.h>
#include<iostream>
#include<string>
#include<memory.h>
#include<limits.h>
#include<stack>
using namespace std;
vector<int> weight;
bool cmp(const int&a, const int&b)
{
return weight[a] > weight[b];
}
/*
11 3
25 18 0 46 37 3 19 22 57 56 10
6 0 8 7 10 5 9 1 4 2 3
11 3
25 18 0 46 37 3 19 22 57 56 10
0 1 2 3 4 5 6 7 8 9 10
11 11
25 18 0 46 37 3 19 22 57 56 10
0 1 2 3 4 5 6 7 8 9 10
11 10
25 18 0 46 37 3 19 22 57 56 10
0 1 2 3 4 5 6 7 8 9 10
11 10
0 1 2 3 4 5 6 7 8 9 10
0 1 2 3 4 5 6 7 8 9 10
10 5
0 1 2 3 4 5 6 7 8 9
0 1 2 3 4 5 6 7 8 9
10 4
0 1 2 3 4 5 6 7 8 9
0 1 2 3 4 5 6 7 8 9
10 3
0 1 2 3 4 5 6 7 8 9
0 1 2 3 4 5 6 7 8 9
10 2
0 1 2 3 4 5 6 7 8 9
0 1 2 3 4 5 6 7 8 9
10 1
0 1 2 3 4 5 6 7 8 9
0 1 2 3 4 5 6 7 8 9
*/
int main(void)
{
int NP, NG;
cin >> NP >> NG;
weight = vector<int>(NP, 0);
vector<int> order(NP, 0);
vector<int> rank(NP, 0);
for (int i = 0; i < NP; i++)
{
scanf("%d", &weight[i]);//输入老鼠重量
}
for (int i = 0; i < NP; i++)
{
scanf("%d", &order[i]);//输入选手的次数,order[i]号选手在i的位置
}
int thisCount = NP ;
while (1)
{
int group;
if (thisCount%NG == 0)
group = thisCount / NG;
else
group = thisCount / NG + 1;
//如果只有0组,或者刚好1组,则全部排名即可
if (group <= 1)
{
sort(order.begin(), order.begin() + thisCount, cmp);
rank[order[0]] = 1;//最后一轮,胜利者为第一名
for (int i = 1; i < thisCount; i++)
{//其他落败的名次相同,均为第2名
rank[order[i]] = 2;
}
break;
}
else
{
int nextCount=0;
for (int i = 0; i < group; i++)
{
int maxNum = order[i*NG];
int maxWeight = weight[maxNum];
for (int j = i*NG + 1; j < min((i + 1)*NG, thisCount); j++)
{
if (maxWeight < weight[order[j]])
{//max落败
rank[maxNum] = group + 1;
maxWeight = weight[order[j]];
maxNum = order[j];
}
else
{//j落败
rank[order[j]] = group + 1;
}
}
//为了节省空间,把排名放在order的0~group-1的位置,不会干扰
order[nextCount++]=maxNum;
}
thisCount = group;
}
}
for (int i = 0; i < rank.size(); i++)
{
printf("%d", rank[i]);
if (i != rank.size()-1)
printf(" ");
}
cout << endl;
return 0;
}
[/c]